LILA BC (Labeled Information Library of Alexandria: Biology and Conservation)
LILA BC is a repository for data sets related to biology and conservation, intended as a resource for both machine learning (ML) researchers and those that want to harness ML for biology and conservation. LILA BC is intended to host data from a variety of modalities, but emphasis is placed on labeled images; we currently host over ten million labeled images.LILA BC
The Labeled Information Library of Alexandria: Biology and Conservation

Overview
LILA BC is a repository for data sets related to biology and conservation, intended as a resource for both machine learning researchers and those that want to harness ML for biology and conservation. All datasets are available within the following S3 folder:
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife
About half of the datasets on LILA contain images from motion-triggered wildlife cameras (aka “camera traps”); those datasets are interoperable, use a consistent metadata format, and have been mapped to a common taxonomy, such that although they are presented as separate datasets, all the camera trap datasets can be treated as a single dataset for training and evaluating ML models. Consequently, this collection is divided into two sections: camera trap datasets and non-camera-trap datasets. More information about the harmonization of camera trap datasets on LILA is available here.
We ask that if you use a data set hosted on LILA BC, you give credit to the data set owner in the manner listed in the data set’s documentation.
For more information, or to inquire about adding a data set, email info@lila.science.
We also maintain a list of other labeled data sets related to conservation.
LILA BC is maintained by a working group that includes representatives from Ecologize, Zooniverse, the Evolving AI Lab, and Snapshot Safari.
Data is available on AWS, GCP, and Azure. Hosting on AWS is provided by Source Cooperative. Hosting on Google Cloud is provided by the Google Cloud Public Datasets program. Hosting on Microsoft Azure is provided by the Microsoft AI for Good Lab.
Table of contents
- North American Camera Trap Images
- Caltech Camera Traps
- Wellington Camera Traps
- Missouri Camera Traps
- WCS Camera Traps
- Snapshot Serengeti
- ENA24-detection
- Snapshot Kruger
- Snapshot Mountain Zebra
- Snapshot Camdeboo
- Snapshot Enonkishu
- Snapshot Kgalagadi
- Snapshot Karoo
- Island Conservation Camera Traps
- Channel Islands Camera Traps
- Idaho Camera Traps
- SWG Camera Traps 2018-2020
- Orinoquía Camera Traps
- Lindenthal Camera Traps
- New Zealand Wildlife Thermal Imaging
- Trail Camera Images of New Zealand Animals
- Desert Lion Conservation Camera Traps
- Ohio Small Animals
- Snapshot Safari 2024 Expansion
- Seattle(ish) Camera Traps
- UNSW Predators
- Chesapeake Land Cover
- Amur Tiger Re-identification
- Conservation Drones
- Forest Canopy Height in Mexican Ecosystems
- Adirondack Research Invasive Species Mapping
- Whale Shark ID
- Great Zebra and Giraffe Count and ID
- HKH Glacier Mapping
- Aerial Seabirds West Africa
- GeoLifeCLEF 2020
- WNI Giraffes
- Forest Damages - Larch Casebearer
- Boxes on Bees and Pollen
- NOAA Arctic Seals 2019
- Leopard ID 2022
- Hyena ID 2022
- Beluga ID 2022
- NOAA Puget Sound Nearshore Fish 2017-2018
- Izembek Lagoon Waterfowl
- Sea Star Re-ID 2023
- UAS Imagery of Migratory Waterfowl at New Mexico Wildlife Refuges
Camera trap datasets
North American Camera Trap Images
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nacti-unzipped
Overview
This data set contains 3.7M camera trap images from five locations across the United States, with labels for 28 animal categories, primarily at the species level (for example, the most common labels are cattle, boar, and red deer). Approximately 12% of images are labeled as empty. We have also added bounding box annotations to 8892 images (mostly vehicles and birds).
Citation, license, and contact information
More information about this data set is available in the associated manuscript:
Tabak MA, Norouzzadeh MS, Wolfson DW, Sweeney SJ, VerCauteren KC, Snow NP, Halseth JM, Di Salvo PA, Lewis JS, White MD, Teton B. Machine learning to classify animal species in camera trap images: Applications in ecology. Methods in Ecology and Evolution. 2019 Apr;10(4):585-90.
Please cite this manuscript if you use this data set.
This data set is released under the Community Data License Agreement (permissive variant).
For questions about this data set, contact northamericancameratrapimages@gmail.com.
Data format
Annotations are provided in COCO Camera Traps .json format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/nacti-unzipped (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nacti-unzipped (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/nacti-unzipped (Azure)
Links to a series of zipfiles are also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
GCP links
Images (1/4) (488GB)
Images (2/4) (343GB)
Images (3/4) (347GB)
Images (4/4) (191GB)
Metadata (.json) (44MB)
Metadata (.csv) (31MB)
Bounding boxes (363KB)
Azure links
Images (1/4) (488GB)
Images (2/4) (343GB)
Images (3/4) (347GB)
Images (4/4) (191GB)
Metadata (.json) (44MB)
Metadata (.csv) (31MB)
Bounding boxes (363KB)
AWS links
Images (1/4) (488GB)
Images (2/4) (343GB)
Images (3/4) (347GB)
Images (4/4) (191GB)
Metadata (.json) (44MB)
Metadata (.csv) (31MB)
Bounding boxes (363KB)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Caltech Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/caltech-unzipped
Overview
This data set contains 243,100 images from 140 camera locations in the Southwestern United States, with labels for 21 animal categories (plus empty), primarily at the species level (for example, the most common labels are opossum, raccoon, and coyote), and approximately 66,000 bounding box annotations. Approximately 70% of images are labeled as empty.
More information about this data set is available here.
Citation, license, and contact information
If you use this data set, please cite the associated manuscript:
Sara Beery, Grant Van Horn, Pietro Perona. Recognition in Terra Incognita. Proceedings of the 15th European Conference on Computer Vision (ECCV 2018). (bibtex)
This data set is released under the Community Data License Agreement (permissive variant).
For questions about this data set, contact caltechcameratraps@gmail.com.
Data format
Annotations are provided in COCO Camera Traps .json format.
We have also divided locations (i.e., cameras) into training and validation splits to allow for consistent benchmarking on this data set. The file describing this split specifies a train/val split for all locations in the data set, and also provides the train/val split used in the ECCV paper listed above. The "eccv_train" split here corresponds to the "train" locations and all "cis" locations in the ECCV paper; the "eccv_val" split here corresponds to all "trans" locations in the ECCV paper.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/caltech-unzipped/cct_images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/caltech-unzipped/cct_images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/caltech-unzipped/cct_images (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
- Images (105GB) (GCP link) (Azure link) (AWS link)
Metadata download links:
- Image-level annotations (9MB)
- Bounding box annotations (35MB)
- Recommended train/val splits (4KB)
Having trouble downloading? Check out our FAQ.
CCT20 Benchmark subset
The initial publication of this data set in Beery et al. 2018 proposed a specific subset of Caltech Camera Traps data for benchmarking. Images in this benchmark dataset (CCT20) have been downsized to a maximum of 1024 pixels on a side.
The CCT20 benchmark set is available here:
Benchmark images (6GB)
Metadata files for train/val/cis/trans splits (3MB)
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Wellington Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wellington-unzipped
Overview
This data set contains 270,450 images from 187 camera locations in Wellington, New Zealand. The cameras (Bushnell 119537, 119476, and 119436) recorded sequences of three images when triggered. Each sequence was labelled by citizen scientists and/or professional ecologists from Victoria University of Wellington into 17 classes: 15 animal categories (for example, the most common labels are bird, cat, and hedgehog), empty, and unclassifiable. Approximately 17% of images are labeled as empty. Images within each sequence share the same species label (even though the animal may not have been recorded in all three images).
Citation, license, and contact information
If you use this data set, please cite the associated manuscript:
Victor Anton, Stephen Hartley, Andre Geldenhuis, Heiko U Wittmer 2018. Monitoring the mammalian fauna of urban areas using remote cameras and citizen science. Journal of Urban Ecology; Volume 4, Issue 1.
This data set is released under the Community Data License Agreement (permissive variant).
For questions about this data set, contact Victor Anton.
Data format
Annotations are provided in .csv format as well as in COCO Camera Traps .json format. In the .csv format, empty images are referred to as “nothinghere”; in the .json format, empty images are referred to as “empty” for consistency with other data sets on this site.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/wellington-unzipped/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wellington-unzipped/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/wellington-unzipped/images (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Download links:
GCP links: images (176GB), .json metadata (8MB), .csv metadata (4MB)
Azure links: images (176GB), .json metadata (8MB), .csv metadata (4MB)
AWS links: images (176GB), .json metadata (8MB), .csv metadata (4MB)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Missouri Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/missouricameratraps
Overview
This data set contains approximately 25,000 camera trap images representing 20 species (for example, the most common labels are red deer, mouflon, and white-tailed deer). Images within each sequence share the same species label (even though the animal may not have been recorded in all the images in the sequence). Around 900 bounding boxes are included. These are very challenging sequences with highly cluttered and dynamic scenes. Spatial resolutions of the images vary from 1920 × 1080 to 2048 × 1536. Sequence lengths vary from 3 to more than 300 frames.
Citation, license, and contact information
If you use this data set, please cite the associated manuscript:
Zhang, Z., He, Z., Cao, G., & Cao, W. (2016). Animal detection from highly cluttered natural scenes using spatiotemporal object region proposals and patch verification. IEEE Transactions on Multimedia, 18(10), 2079-2092. (bibtex)
This data set is released under the Community Data License Agreement (permissive variant).
For questions about this data set, contact Hayder Yousif and Zhi Zhang.
Update: it appears that those email addresses no longer work, but I don't feel quite right removing them from the page, so I'm leaving them crossed out for posterity. For most questions about this dataset, info@lila.science can help.
Data format
Annotations are provided in the COCO Camera Traps .json format used for most data sets on lila.science. Note that due to some issues in the source data (see below), bounding boxes are accurate, but for images that have multiple individuals in them, a bounding box is present for only one. For these images, we have added a non-standard field to the .json file ("n_boxes") which indicates the number of animals that actually exist in the image, even though a bounding box is present for only one. We hope to fix this at some point, and it's only 79 images, and we know exactly which ones they are (here's a list), so if someone wants to send us updated bounding boxes for those images, we will (a) update the .json file and (b) buy you a fancy coffee.
Annotations are also provided in the whitespace-delimited text format used by the authors (inside the zipfile, along with a README documenting its format), though we recommend using the .json file; the filenames in the text file don't correspond precisely to the image filenames, and (as per above) most images that have multiple animals include redundant bounding boxes, rather than multiple unique bounding boxes.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/missouricameratraps/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/missouricameratraps/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/missouricameratraps/images (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Download links:
Images (10GB) (GCP link) (Azure link) (AWS link)
Metadata (.json, 1MB) (GCP link) (Azure link) (AWS link)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

WCS Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wcs-unzipped
Overview
This data set contains approximately 1.4M camera trap images representing around 675 species from 12 countries, making it one of the most diverse camera trap data sets available publicly. Data were provided by the Wildlife Conservation Society. The most common classes are tayassu pecari (peccary), meleagris ocellata (ocellated turkey), and bos taurus (cattle). A complete list of classes and associated image counts is available here. Approximately 50% of images are empty. We have also added approximately 375,000 bounding box annotations to approximately 300,000 of those images, which come from sequences covering almost all locations.
Sequences are inferred from timestamps, so may not strictly represent bursts. Images were labeled at a combination of image and sequence level, so – as is the case with most camera trap data sets – empty images may be labeled as non-empty (if an animal was present in one frame of a sequence but not in others). Images containing humans are referred to in metadata, but are not included in the data files.
Contact information
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations are provided in the COCO Camera Traps .json format used for most data sets on lila.science.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Accessing the data
Class-level annotations are available here:
Bounding box annotations are available here:
wcs_20220205_bboxes_with_classes.zip (with the same classes as the class-level labels)
wcs_20220205_bboxes_no_classes.zip (with just animal/person/vehicle labels)
Recommended train/val/test splits are available here:
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/wcs-unzipped (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wcs-unzipped (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/wcs-unzipped (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, one image (with lots of birds) appears in the metadata as:
animals/0011/0009.jpg
This image can be downloaded directly from any of the following URLs (one for each cloud):
https://storage.googleapis.com/public-datasets-lila/wcs-unzipped/animals/0011/0009.jpg
{kind=link}
{kind=link}
https://lilawildlife.blob.core.windows.net/lila-wildlife/wcs-unzipped/animals/0011/0009.jpg
{kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Serengeti
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshotserengeti-unzipped
Overview
This data set contains approximately 2.65M sequences of camera trap images, totaling 7.1M images, from seasons one through eleven of the Snapshot Serengeti project, the flagship project of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Serengeti National Park in Tanzania is best known for the massive annual migrations of wildebeest and zebra that drive the cycling of its dynamic ecosystem.
Labels are provided for 61 categories, primarily at the species level (for example, the most common labels are wildebeest, zebra, and Thomson's gazelle). Approximately 76% of images are labeled as empty. A full list of species and associated image counts is available here. We have also added approximately 150,000 bounding box annotations to approximately 78,000 of those images.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
The images and species-level labels are described in more detail in the associated manuscript:
Swanson AB, Kosmala M, Lintott CJ, Simpson RJ, Smith A, Packer C (2015) Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Scientific Data 2: 150026. (DOI) (bibtex)
Please cite this manuscript if you use this data set.
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original Snapshot Serengeti data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format. .json files are provided for each season, and a single .json file is also provided for all seasons combined. Note that annotations are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
Annotations are also provided in a (non-standard) .csv format. These are intended to allow replication of the original dataset paper, but they have not been maintained as diligently as the .json files and their format has not been documented, so unless you have a strong reason to use the .csv files, we recommend using the .json files.
Additional metadata related to the aggregation of human labels into consensus labels is available in an addendum.
We have also divided locations (i.e., cameras) into training and validation splits to allow for consistent benchmarking on this data set.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/snapshotserengeti-unzipped (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshotserengeti-unzipped (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshotserengeti-unzipped (Azure)
A link to a zipfile per season is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 (242GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 2 (382GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 3 (25`GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 4 (368GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 5 (596GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 6 (361GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 7 (636GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 8 (part 1) (450GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 8 (part 2) (414GB) (images, GCP) (images, Azure) (images, AWS)
Season 9 (part 1) (432GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 9 (part 2) (432GB) (images, GCP) (images, Azure) (images, AWS)
Season 10 (part 1) (500GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Season 10 (part 2) (166GB) (images, GCP) (images, Azure) (images, AWS)
Season 11 (479GB) (images, GCP) (images, Azure) (images, AWS) (metadata)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

ENA24-detection
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/ena24
Overview
This data set contains approximately 10,000 camera trap images representing 23 classes from Eastern North America, with bounding boxes on each image. The most common classes are "American Crow", "American Black Bear", and "Dog".
Citation, license, and contact information
This data set is released under the Community Data License Agreement (permissive variant).
The data set is described in more detail in the associated manuscript:
Yousif H, Kays R, Zhihai H. Dynamic Programming Selection of Object Proposals for Sequence-Level Animal Species Classification in the Wild. IEEE Transactions on Circuits and Systems for Video Technology, 2019. (bibtex)
Please cite this manuscript if you use this data set.
For questions about this data set, contact Hayder Yousif.
Data format
Annotations are provided in the COCO Camera Traps .json format used for most data sets on lila.science. Images containing humans were removed from the data set, but the metadata still contains information about those images.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/ena24/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/ena24/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/ena24/images (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Download links:
Images (GCP, 3.6GB)
Metadata (GCP, 3.6MB)
Images (Azure, 3.6GB)
Metadata (Azure 3.6MB)
Images (AWS, 3.6GB)
Metadata (AWS, 3.6MB)
An "unofficial" version of the metadata file that only includes annotations for images that are present in the public data set (i.e., from which metadata for images of humans has been removed) is available at:
Metadata (non-human images only) (2.9MB)
It is not guaranteed that this version will be maintained across changes to the underlying data set, but we're like 99.9999999% sure that if you're reading this, it's still accurate.
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Kruger
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KRU
Overview
This data set contains 4747 sequences of camera trap images, totaling 10072 images, from the Snapshot Kruger project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Kruger National Park, South Africa has been a refuge for wildlife since its establishment in 1898, and it houses one of the most diverse wildlife assemblages remaining in Africa. The Snapshot Safari grid was established in 2018 as part of a research project assessing the impacts of large mammals on plant life as boundary fences were removed and wildlife reoccupied areas of previous extirpation.
Labels are provided for 46 categories, primarily at the species level (for example, the most common labels are impala, elephant, and buffalo). Approximately 61.60% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/KRU/KRU_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KRU/KRU_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/KRU/KRU_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (28GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (28GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (28GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Mountain Zebra
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/MTZ
Overview
This data set contains 71688 sequences of camera trap images, totaling 73034 images, from the Snapshot Mountain Zebra project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Mountain Zebra National Park is located in the Eastern Cape of South Africa in a transitional area between several distinct biomes, which means it is home to many endemic species. As the name suggests, this park contains the largest remnant population of Cape Mountain zebras, ~700 as of 2019 and increasing steadily every year.
Labels are provided for 54 categories, primarily at the species level (for example, the most common labels are zebramountain, kudu, and springbok). Approximately 91.23% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/MTZ/MTZ_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/MTZ/MTZ_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/MTZ/MTZ_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (109GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (109GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (109GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Camdeboo
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/CDB
Overview
This data set contains 12132 sequences of camera trap images, totaling 30227 images, from the Snapshot Camdeboo project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Camdeboo National Park, South Africa is crucial habitat for many birds on a global scale, with greater than fifty endemic and near-endemic species and many migratory species.
Labels are provided for 43 categories, primarily at the species level (for example, the most common labels are kudu, springbok, and ostrich). Approximately 43.74% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/CDB/CDB_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/CDB/CDB_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/CDB/CDB_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (33GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (33GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (33GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Enonkishu
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/ENO
Overview
This data set contains 13301 sequences of camera trap images, totaling 28544 images, from the Snapshot Enonkishu project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Enonkishu Conservancy is located on the northern boundary of the Mara-Serengeti ecosystem in Kenya, and is managed by a consortium of stakeholders and land-owning Maasai families. Their aim is to promote coexistence between wildlife and livestock in order to encourage regenerative grazing and build stability in the Mara conservancies.
Labels are provided for 39 categories, primarily at the species level (for example, the most common labels are impala, warthog, and zebra). Approximately 64.76% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/ENO/ENO_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/ENO/ENO_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/ENO/ENO_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (32GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (32GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (32GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Kgalagadi
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KGA
Overview
This data set contains 3611 sequences of camera trap images, totaling 10222 images, from the Snapshot Kgalagadi project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. The Kgalagadi Transfrontier Park stretches from the Namibian border across South Africa and into Botswana, covering a landscape commonly referred to as the Kalahari – an arid savanna. This region is of great interest to help us understand how animals cope with extreme temperatures at both ends of the scale.
Labels are provided for 31 categories, primarily at the species level (for example, the most common labels are gemsbokoryx, birdother, and ostrich). Approximately 76.14% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/KGA/KGA_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KGA/KGA_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/KGA/KGA_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (10GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (10GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (10GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Karoo
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KAR
Overview
This data set contains 14889 sequences of camera trap images, totaling 38074 images, from the Snapshot Karoo project, part of the Snapshot Safari network. Using the same camera trapping protocols at every site, Snapshot Safari members are collecting standardized data from many protected areas in Africa, which allows for cross-site comparisons to assess the efficacy of conservation and restoration programs. Karoo National Park, located in the arid Nama Karoo biome of South Africa, is defined by its endemic vegetation and mountain landscapes. Its unique topographical gradient has led to a surprising amount of biodiversity, with 58 mammals and more than 200 bird species recorded, as well as a multitude of reptilian species.
Labels are provided for 38 categories, primarily at the species level (for example, the most common labels are gemsbokoryx, hartebeestred, and kudu). Approximately 83.02% of images are labeled as empty. A full list of species and associated image counts is available here.
Additional data from this project is available as part of the Snapshot Safari 2024 Expansion dataset.
Citation, license, and contact information
For questions about this data set, contact Sarah Huebner at the University of Minnesota.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a "human" class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps .json format, as well as .csv format. Note that annotations in the .json format are tied to images, but are only reliable at the sequence level. For example, there are rare sequences in which two of three images contain a lion, but the third is empty (lions, it turns out, walk away sometimes), but all three images would be annotated as "lion".
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Images are available in the following cloud folders:
- gs://public-datasets-lila/snapshot-safari/KAR/KAR_public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari/KAR/KAR_public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari/KAR/KAR_public (Azure)
A link to a zipfile is also provided below, but - whether you want the whole data set, a specific folder, or a subset of the data (e.g. images for one species) - we recommend checking out our guidelines for accessing images without using giant zipfiles.
Data download links:
Season 1 images (40GB) (.json metadata) (.csv metadata) (GCP)
Season 1 images (40GB) (.json metadata) (.csv metadata) (Azure)
Season 1 images (40GB) (.json metadata) (.csv metadata) (AWS)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Island Conservation Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/islandconservationcameratraps
Overview
This data set contains approximately 123,000 camera trap images from 123 camera locations from 7 islands in 6 countries. Data were provided by Island Conservation during projects conducted to prevent the extinction of threatened species on islands.
The most common classes are rabbit, rat, petrel, iguana, cat, goat, and pig, with both rat and cat represented between multiple island sites representing significantly different ecosystems (tropical forest, dry forest, and temperate forests). Additionally, this data set represents data from locations and ecosystems that, to our knowledge, are not well represented in publicly available datasets including >1,000 images each of iguanas, petrels, and shearwaters. A complete list of classes and associated image counts is available here. Approximately 60% of the images are empty. We have also included approximately 65,000 bounding box annotations for about 50,000 images.
In general cameras were dispersed across each project site to detect the presence of invasive vertebrate species that threaten native island species. Cameras were set to capture bursts of photos for each motion detection event (between three and eight photos) with a set delay between events (10 to 30 seconds) to minimize the number of photos. Images containing humans are referred to in metadata, but are not included in the data files.
Citation, license, and contact information
For questions about this data set, contact David Will at Island Conservation.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a “human” class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata. If those images are important to your work, contact us; in some cases it will be possible to release those images under an alternative license.
Data format
Annotations are provided in COCO Camera Traps format. Timestamps were not present in the original data package, and have been inferred from image pixels using an OCR approach. Let us know if you see any incorrect timestamps.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here (5MB).
Images are available as a single zipfile:
Download from GCP (76GB)
Download from AWS (76GB)
Download from Azure (76GB)
Images are also available (unzipped) in the following cloud storage folders:
- gs://public-datasets-lila/islandconservationcameratraps/public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/islandconservationcameratraps/public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/islandconservationcameratraps/public (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Channel Islands Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/channel-islands-camera-traps
Overview
This data set contains 246,529 camera trap images from 73 camera locations in the Channel Islands, California. All animals are annotated with bounding boxes. Data were provided by The Nature Conservancy.
Animals are classified as rodent1 (82914), fox (48150), bird (11099), skunk (1071), or other (159). 114,949 images (47%) are empty.
1All images of rats were taken on islands already known to have rat populations.
Citation, license, and contact information
If you use these data in a publication or report, please use the following citation:
The Nature Conservancy (2021): Channel Islands Camera Traps 1.0. The Nature Conservancy. Dataset.
For questions about this data set, contact Nathaniel Rindlaub at The Nature Conservancy.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a “human” class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata.
Data format
Annotations are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here (18MB).
Images are available as a single zipfile:
Download from GCP (86GB)
Download from AWS (86GB)
Download from Azure (86GB)
Images are also available (unzipped) in the following cloud storage folders:
- gs://public-datasets-lila/channel-islands-camera-traps/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/channel-islands-camera-traps/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/channel-islands-camera-traps/images (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Idaho Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/idaho-camera-traps
Overview
This data set contains approximately 1.5 million camera trap images from Idaho. Labels are provided for 62 categories, most of which are animal classes ("deer", "elk", and "cattle" are the most common animal classes), but labels also include some state indicators (e.g. "snow on lens", "foggy lens"). Approximately 70.5% of images are labeled as empty. Annotations were assigned to image sequences, rather than individual images, so annotations are meaningful only at the sequence level.
The metadata contains references to images containing humans, but these have been removed from the dataset (along with images containing vehicles and domestic dogs).
Citation, license, and contact information
Images were provided by the Idaho Department of Fish and Game. No representations or warranties are made regarding the data, including but not limited to warranties of non-infringement or fitness for a particular purpose. Some information shared under this agreement may not have undergone quality assurance procedures and should be considered provisional. Images may not be sold in any format, but may be used for scientific publications. Please acknowledge the Idaho Department of Fish and Game when using images for publication or scientific communication.
Data format
Annotations are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here (25MB).
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/idaho-camera-traps/public (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/idaho-camera-traps/public (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/idaho-camera-traps/public (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, the image referred to in the metadata file as:
loc_0000/loc_0000_im_000003.jpg
...can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Finally, though we don't recommend downloading this way, images are also available in five giant zipfiles:
Images (part 0) (GCP) (AWS) (Azure) (300GB)
Images (part 1) (GCP) (AWS) (Azure) (300GB)
Images (part 2) (GCP) (AWS) (Azure) (300GB)
Images (part 3) (GCP) (AWS) (Azure) (300GB)
Images (part 4) (GCP) (AWS) (Azure) (250GB)
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

SWG Camera Traps 2018-2020
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/swg-camera-traps
Overview
This data set contains 436,617 sequences of camera trap images from 982 locations in Vietnam and Lao, totaling 2,039,657 images. Labels are provided for 120 categories, primarily at the species level (for example, the most common labels are "Eurasian Wild Pig", "Large-antlered Muntjac", and "Unidentified Murid"). Approximately 12.98% of images are labeled as empty. A full list of species and associated image counts is available here. 101,659 bounding boxes are provided on 88,135 images.
This data set is provided by the Saola Working Group; providers include:
- IUCN SSC Asian Wild Cattle Specialist Group’s Saola Working Group (SWG)
- Asian Arks
- Wildlife Conservation Society (Lao)
- WWF Lao
- Integrated Conservation of Biodiversity and Forests project, Lao (ICBF)
- Center for Environment and Rural Development, Vinh University, Vietnam
Citation, license, and contact information
If you use these data in a publication or report, please use the following citation:
SWG (2021): Northern and Central Annamites Camera Traps 2.0. IUCN SSC Asian Wild Cattle Specialist Group’s Saola Working Group. Dataset.
For questions about this data set, contact saolawg@gmail.com.
This data set is released under the Community Data License Agreement (permissive variant).
The original data set included a “human” class label; for privacy reasons, we have removed those images from this version of the data set. Those labels are still present in the metadata.
Data format
Annotations are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Accessing the data
Class-level annotations are available here:
Bounding box annotations are available here:
swg_camera_traps.bounding_boxes.with_species.zip (with the same classes as the class-level labels)
swg_camera_traps.bounding_boxes.no_species.zip (with just animal/person/vehicle labels)
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/swg-camera-traps (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/swg-camera-traps (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/swg-camera-traps (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, the image referred to in the metadata file as:
public/vietnam/loc_0815/2019/06/image_00059.jpg
...can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Orinoquía Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/orinoquia-camera-traps
Overview
This data set contains 104,782 images collected from a 50-camera-trap array deployed from January to July 2020 within the private natural reserves El Rey Zamuro (31 km2) and Las Unamas (40 km2), located in the Meta department in the Orinoquía region in central Colombia. We deployed cameras using a stratified random sampling design across forest core area strata. Cameras were spaced 1 km apart from one another, located facing wildlife trails, and deployed with no bait. Images were stored and reviewed by experts using the Wildlife Insights platform.
This data set contains 51 classes, predominantly mammals such as the collared peccary, black agouti, spotted paca, white-lipped peccary, lowland tapir, and giant anteater. Approximately 20% of images are empty.
The main purpose of the study is to understand how humans, wildlife, and domestic animals interact in multi-functional landscapes (e.g., agricultural livestock areas with native forest remnants). However, this data set was also used to review model performance of AI-powered platforms – Wildlife Insights (WI), MegaDetector (MD), and Machine Learning for Wildlife Image Classification (MLWIC2). We provide a demonstration of the use of WI, MD, and MLWIC2 and R code for evaluating model performance of these platforms in the accompanying GitHub repository:
https://github.com/julianavelez1/Processing-Camera-Trap-Data-Using-AI
The metadata contains references to images containing humans, but these have been removed from the dataset.
Citation, license, and contact information
If you use these data in a publication or report, please use the following citation:
Vélez J, McShea W, Shamon H, Castiblanco‐Camacho PJ, Tabak MA, Chalmers C, Fergus P, Fieberg J. An evaluation of platforms for processing camera‐trap data using artificial intelligence. Methods in Ecology and Evolution. 2023 Feb;14(2):459-77.
For questions about this data set, contact Juliana Velez Gomez.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here (2.4MB).
Images are available as a single zipfile:
Download from GCP (72GB)
Download from AWS (72GB)
Download from Azure (72GB)
Images are also available (unzipped) in the following cloud storage folders:
- gs://public-datasets-lila/orinoquia-camera-traps (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/orinoquia-camera-traps (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/orinoquia-camera-traps (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Lindenthal Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/lindenthal-camera-traps
Overview
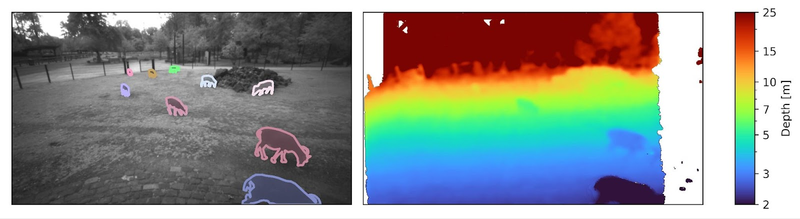
This data set contains 775 video sequences, captured in the wildlife park Lindenthal (Cologne, Germany) as part of the AMMOD project, using an Intel RealSense D435 stereo camera. In addition to color and infrared images, the D435 is able to infer the distance (or “depth”) to objects in the scene using stereo vision. Observed animals include various birds (at daytime) and mammals such as deer, goats, sheep, donkeys, and foxes (primarily at nighttime). A subset of 412 images is annotated with a total of 1038 individual animal annotations, including instance masks, bounding boxes, class labels, and corresponding track IDs to identify the same individual over the entire video.
Citation, license, and contact information
The capture process and dataset is described in more detail in the following preprint:
Haucke T, Steinhage V. Exploiting depth information for wildlife monitoring. arXiv preprint arXiv:2102.05607. 2021 Feb 10.
Please cite this manuscript if you use this data set. For questions about this data set, contact Timm Haucke at the University of Bonn.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
The videos are captured using an Intel RealSense D435 stereo camera and stored as RealSense rosbag files. Each video contains intensity (RGB at daytime, IR at nighttime) and depth image streams with durations of 15 to 45 seconds at 15 frames per second. The depth images are computed on the RealSense D435 in real-time. Sequences recorded from December 17, 2020 additionally contain the raw left / right IR intensity images to facilitate offline stereo correspondence. The file names correspond to the local time, formatted as %Y%m%d%H%M%S.
A subset of videos is labeled with instance masks, bounding boxes, class labels, and track ids in the COCO JSON format. The first 20 frames of the video were skipped during annotation such that the annotated images are not affected by the automatic exposure process of the D435. After two seconds, every 10th frame was annotated with instance masks and track IDs. Together with the COCO JSON annotation files we provide the corresponding extracted still image files in JPEG (intensity) and OpenEXR (depth) format. The included Jupyter Notebook demonstrates how to load and visualize these images and the corresponding annotations.
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (213GB)
Download from AWS (213GB)
Download from Azure (213GB)
Having trouble downloading? Check out our FAQ.
New Zealand Wildlife Thermal Imaging
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nz-thermal
Overview
This dataset contains 121,190 thermal videos, from The Cacophony Project. The Cacophony Project focuses on monitoring native wildlife of New Zealand, with a particular emphasis on detecting and understanding the behaviour of invasive predators such as possums, rodents, cats, hedgehogs, and mustelids. The goal of this work is to conserve and restore native wildlife by eliminating these invasive species from the wild.
The videos were captured across various regions of New Zealand, mostly at night. Video capture was triggered by a change in incident heat; approximately 24,000 videos are labeled as false positives. Labels are provided for 45 categories; the most common (other than false positives) are "bird", "rodent", and "possum". A full list of labels and the number of videos associated with each label is available here (csv).
Benchmark results
Benchmark results on this dataset, with instructions for reproducing those results, are available here.
Citation, license, and contact information
For questions about this dataset, contact coredev@cacophony.org.nz at The Cacophony Project.
This data set is released under the Community Data License Agreement (permissive variant).
No citation is required, but if you find this dataset useful, or you just want to support technology that is contributing to the conservation of New Zealand's native wildlife, consider donating to The Cacophony Project.

Data format
If you prefer tinkering with a notebook to reading documentation, you may prefer to ignore this section, and go right to the sample notebook.
Three versions of each video are available:
- An mp4 video, in which the background has been estimated as the median of the clip, and each frame represents the deviation from that background. This video is referred to as the "filtered" video in the metadata described below. We think this is what most ML folks will want to use. This is not a perfectly faithful representation of the original data, since we've lost information about absolute temperature, and median-filtering isn't a perfect way to estimate background. Nonetheless, this is probably easiest to work with for 99% of ML applications. (example background-subtracted video)
- An mp4 video, in which each frame has been independently normalized. This captures the gestalt of the scene a little better, e.g. you can generally pick out trees. (example non-background-subtracted video)
- An HDF file representing the original thermal data, including - in some cases - metadata that allows the reconstruction of absolute temperature. More complicated to work with, but totally faithful to what came off of the sensor. These files are also more than ten times larger (totaling around 500GB, whereas the compressed mp4's add up to around 35GB), so they are not included in the big zipfile below. We don't expect most ML use cases to need these files.
The metadata file (.json) describes the annotations associated with each video. Annotators were not labeling whole videos with each tag, they were labeling "tracks", which are individual sequences of continuous movement within a video. So in some cases, for example, a single cat might move through the video, disappear behind a tree, and re-appear, in which case the metadata will contain two tracks with the "cat" label. The metadata contains the start/stop frames of each track and the trajectories of those tracks. Tracks are based on thresholding and clustering approaches, i.e., the tracks are themselves machine-generated, but they are generally quite reliable (other than some false positives), and the main focus of this dataset is the classification of tracks and pixels (both movement trajectory and thermal appearance can contribute to species identification), rather than improving tracking.
More specifically the main metadata file contains everything about each clip except the track coordinates, which would make the metadata file very large. Each clip also has its own .json metadata file, which has all the information available in the main metadata file about that clip, as well as the track coordinates.
Clip metadata is stored as a dictionary with an "info" field containing general information about the dataset, and a "clips" field with all the information about the videos. The "clips" field is a list of dicts, each element corresponding to a video, with fields:
- filtered_video_filename: the filename of the mp4 video that has been background-subtracted
- video_filename: the filename of the mp4 video in which each frame has been independently normalized
- hdf_filename: the filename of the HDF file with raw thermal data
- metadata_filename: the filename of the .json file with the same data included in this clip's dictionary in the main metadata file, plus the track coordinates
- width, height
- frame_rate: always 9
- error: usually None; a few HDF files were corrupted, but are kept in the metadata for book-keeping purposes, in which case *only* this field and the HDF filename are populated
- labels: a list of unique labels appearing in this video; technically redundant with information in the "tracks" field, but makes it easier to find videos of a particular category
- location: a unique identifier for the location (camera) from which this video was collected
- id: a unique identifier for this video
- calibration_frames: if non-empty, a list of frame indices in which the camera was self-calibrating; data may be less reliable during these intervals
- tracks: a list of annotated tracks, each of which is a dict with fields "start_frame", "end_frame", "points", and "tags". "tags" is a list of dicts with fields "label" and "confidence". All tags were reviewed by humans, so the "confidence" value is mostly a remnant of an AI model that was used as part of the labeling process, and these values may or may not carry meaningful information. "points" is a list of (x,y,frame) triplets. x and y are in pixels, with the origin at the upper-left of the video. As per above, the "points" array is only available in the individual-clip metadata files, not the main metadata file.
That was a lot. tl;dr: check out the sample notebook.
A recommended train/test split is available here. The train/test split is based on location IDs, but the splits are provided at the level of clip IDs. For a few categories where only a very small number of examples exist, those examples were divided across the splits (so a small number of locations appear in both train and test, but only for a couple of categories).
The format of the HDF files is described here. The script used to convert the HDF files to json/mp4 is available here.
Downloading the data
The main metadata, individual clip metadata, and mp4 videos are all available in a single zipfile:
Download metadata, mp4 videos from GCP (33GB)
Download metadata, mp4 videos from AWS (33GB)
Download metadata, mp4 videos from Azure (33GB)
If you just want to browse the main metadata file, it's available separately at:
metadata (5MB)
The HDF files are not available as a zipfile, but are available in the following cloud storage folders:
- gs://public-datasets-lila/nz-thermal/hdf (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nz-thermal/hdf (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/nz-thermal/hdf (Azure)
The unzipped mp4 files are available in the following cloud storage folders:
- gs://public-datasets-lila/nz-thermal/videos (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nz-thermal/videos (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/nz-thermal/videos (Azure)
For example, the clip with ID 1486055 is available at the following URLs (the non-background-subtracted mp4, background-subtracted mp4, and HDF file, respectively):
- https://storage.googleapis.com/public-datasets-lila/nz-thermal/videos/1486055.mp4
- https://storage.googleapis.com/public-datasets-lila/nz-thermal/videos/1486055_filtered.mp4
- https://storage.googleapis.com/public-datasets-lila/nz-thermal/hdf/1486055.hdf5
...or the following gs URLs (for use with, e.g., gsutil):
- gs://public-datasets-lila/nz-thermal/videos/1486055.mp4
- gs://public-datasets-lila/nz-thermal/videos/1486055_filtered.mp4
- gs://public-datasets-lila/nz-thermal/hdf/1486055.hdf5
Having trouble downloading? Check out our FAQ.
Neat thermal camera trap image

Trail Camera Images of New Zealand Animals
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nz-trailcams
Overview
This data set contains approximately 2.5 million camera trap images from various projects across New Zealand. These projects were run by various organizations and took place in a diverse range of habitats using a variety of trail camera brands/models. Most images have been labeled by project staff and then verified by volunteers.
Labels are provided for 97 categories, primarily at the species level. For example, the most common labels are mouse (49% of images), possum (6.7%), and rat (5.5%). No empty images are provided, but some can be made available upon request. A full list of species and associated image counts is available here.
This dataset is a subset of a larger collection; an expanded version of this data can be downloaded directly from:
s3://doc-trail-camera-footage
We will periodically update the LILA dataset to keep up with the source bucket, but if you need the latest and largest, consider downloading directly from the source.
License and contact information
For questions about this data set, contact Joris Tinnemans.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
Species information is also present in folder names (e.g. "AIV/yellow_eyed_penguin"), and location identifiers are also available in the EXIF "ImageDescription" tag for each image.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/nz-trailcams (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/nz-trailcams (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/nz-trailcams (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, the thumbnail below appears in the metadata as:
AIV/yellow_eyed_penguin/7E7FAB4D-C1DB-4445-8CB0-4412AFE2C71D_000005.jpg
This image can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Desert Lion Conservation Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/desert-lion-camera-traps
Overview
This dataset contains 65,959 images and 199 videos from the Desert Lion Conservation Project in Northern Namibia. Desert Lion Conservation is a small non-profit organisation dedicated to the conservation of desert-adapted lions. Their main focus is to collect important baseline ecological data on the lion population and to study their behaviour, biology, and adaptation to survive in the harsh environment. They use this information to collaborate with other conservation bodies in the quest to find a solution to human-lion conflict, to elevate the tourism value of lions, and to contribute to the conservation of the species.
Labels are provided for 46 categories, primarily at the species level. There are no images annotated as empty.
License and contact information
For questions about this data set, contact Peter van Lunteren.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in a zipfile here, and unzipped images are available in the following cloud storage folders:
- gs://public-datasets-lila/desert-lion-camera-traps/annotated-imgs (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/desert-lion-camera-traps/annotated-imgs (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/desert-lion-camera-traps/annotated-imgs (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download individual images via http, you can. For example, the thumbnail below appears in the metadata as:
panthera leo/Camera Trap/2017/02/PvL_seq_d8579c60-9f99-4779-8792-2395ab0e3afa/20170218-PICT0729.JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Ohio Small Animals
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/osu-small-animals
Overview
This dataset contains 118,554 images from AHDriFT camera traps in Ohio. The AHDriFT system uses a fence to guide small animals into an enclosure containing a downward-facing camera.
Labels are provided for 45 species. The most common labels are Eastern garter snake (31,899 images), song sparrow (14,567 images), meadow vole (14,169 images), and blank (11,448 images).
There are 168 unique location IDs in the dataset, each representing a camera. Two or three cameras placed in a linear or Y-array make up a deployment; for example, the location IDs "KPC1", "KPC2", and "KPC3" are different cameras in the same deployment.
Citation, license, and contact information
If you use this dataset, please cite:
Balasubramaniam S. Optimized Classification in Camera Trap Images: An Approach with Smart Camera Traps, Machine Learning, and Human Inference. Master’s thesis, The Ohio State University. 2024.
For questions about this data set, contact Greg Lipps.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in a zipfile (28GB), and unzipped images are available in the following cloud storage folders:
- gs://public-datasets-lila/osu-small-animals (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/osu-small-animals (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/osu-small-animals (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download individual images via http, you can. For example, the thumbnail below appears in the metadata as:
Images/Sorted_by_species/Mammalia/Eastern Chipmunk/FCM2__2019-09-22__16-47-01(2).JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
https://storage.googleapis.com/public-datasets-lila/osu-small-animals/Images/Sorted_by_species/Mammalia/Eastern Chipmunk/FCM2__2019-09-22__16-47-01(2).JPG
http://us-west-2.opendata.source.coop.s3.amazonaws.com/agentmorris/lila-wildlife/osu-small-animals/Images/Sorted_by_species/Mammalia/Eastern Chipmunk/FCM2__2019-09-22__16-47-01(2).JPG
https://lilawildlife.blob.core.windows.net/lila-wildlife/osu-small-animals/Images/Sorted_by_species/Mammalia/Eastern Chipmunk/FCM2__2019-09-22__16-47-01(2).JPG
Having trouble downloading? Check out our FAQ.
Other useful links
Information about mapping camera trap datasets to a common taxonomy is available here.

Snapshot Safari 2024 Expansion
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari-2024-expansion
Overview
This dataset contains 4,029,374 images from 15 camera trapping projects in the the Snapshot Safari program. Short descriptions of individual projects are provided below, in the project descriptions section.
Labels are provided for 151 categories. The most common labels are "empty" (2,739,081 instances), "impala" (231,564 instances), and "zebra" (122,067 instances). Animal counts are provided for 1,322,468 of the category labels.
There are 1824 unique location IDs in the dataset, each representing a camera.
License, and contact information
For questions about this data set, contact Sarah Huebner at the Smithsonian Institution.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/snapshot-safari-2024-expansion (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/snapshot-safari-2024-expansion (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/snapshot-safari-2024-expansion (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download individual images via http, you can. For example, the thumbnail below appears in the metadata as:
KAR/KAR_S2/C01/C01_R2/KAR_S2_C01_R2_IMAG0210.JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.
Project descriptions
It's not typically necessary to break out images from individual Snapshot Safari projects for model training; i.e., if you want to train a model on images of elands, you probably just want all the images with elands. However, for some cross-validation scenarios it may be helpful to have some context for the individual projects, so in this section, we provide short descriptions of the projects that are represented in this dataset). The three-letter codes presented here for each project correspond to the three-letter prefixes used in image filenames; for example, the filename used above begins with "KAR", which corresponds to the "Snapshot Karoo" project.
Snapshot APNR (APN) (South Africa)
The Associated Private Nature Reserves are an alliance of privately owned reserves that border Kruger National Park and have removed boundary fences to allow ~150 mammal species more room to roam and forage. The camera trap grid in the APNR aligns with the Snapshot Kruger grid to provide an east-west transect across the mopaneveld and mixed broadleaf woodland sections of KNP.
Snapshot Camdeboo (CDB) (South Africa)
Camdeboo National Park is located in the Eastern Cape province of South Africa. It is one of the largest conservancies in the arid Nama Karoo ecoregion, which is dominated by low-shrubbed vegetation and rugged rock formations.
Snapshot Cameo (NIA) (Mozambique)
Niassa Special Reserve is located in northern Mozambique is recognized as a critical protected area and covers more than 42,000 km2, making it larger than Switzerland. Biodiversity surveys have revealed a species-rich and largely intact ecosystem of miombo woodlands, rivers, inselbergs, wetlands, and plains.
Snapshot Enonkishu (ENO) (Kenya)
Enonkishu Conservancy is located in Kenya on the northern boundary of the Mara-Serengeti ecosystem, and promotes the coexistence between wildife and livestock as an essential component of stability in the Mara landscaope.
Snapshot Karoo (KAR) (South Africa)
Karoo National Park was established to preserve a representative samples of the arid Nama Karoo biome. The park features a distinctive topographical gradient due to the mountain range forming its northern boundary.
Snapshot Kgalagadi (KGA) (South Africa)
The Kgalagadi Transfrontier Park stretches from the Namibian border across South Africa and into Botswana, covering a landscape commonly referred to as the Kalahari - an arid savanna.
Snapshot Kruger (KRU) (South Africa)
Kruger National Park is one of the oldest nature reserves in Africa and home to nearly 150 mammal species, including all of the big cats and megaherbivore guild. The camera trap grid in Kruger comprises an east-west transect across the mopaneveld and mixed woodland sections of the park and connects with the grid in the APNR.
Snapshot LEC (LEC) (Botswana)
Leopard Ecology and Conservation is a non-profit organization working in Khutse Game Reserve, Botswana to understand the status and habitat needs of leopards and lions within and outside formal conservation areas in the Kalahari region.
Snapshot Madikwe (MAD) (South Africa)
Madikwe Game Reserve is home to the "Big Five" (lions, elephants, rhinoceros, leopards, and buffalo) as well as cheetahs and wild dogs. Around 10,000 mammals have been relocated there from South Africa national parks.
Snapshot Mountain Zebra (MTZ) (South Africa)
Home to the endangered Cape Mountain zebra, this park was created with the express purpose of saving this population. This has been a success with zebra numbers increasing steadily.
Snapshot Pilanesberg (PLN) (South Africa)
Pilanesberg National Park is situated close to Johannesburg and Pretoria in South Africa, making it highly accessible for visitors. It is situated in the ecologically rich transition zone between the Kalahari and Lowveld on top of an extinct volcano known as the Pilanesberg National Park Alkaline Ring Complex. It is one of the largest volcanic complexes of this type in the world, featuring rare rock types and formations.
Snapshot Ruaha (RUA) (Tanzania)
Ruaha National Park is at the intersection of the Eastern African and Southern African eco-regions, making it a biodiversity hotspot. The greater Ruaha landscape holds around a tenth of the world's lions, as well as large populations of wild dogs, cheetah, and other carnivores.
Snapshot Serengeti (SER) (Tanzania)
Snapshot Safari's flagship project in Serengeti National Park, Tanzania has been collecting continuous camera trap data on lions and the entire wildlife assemblage since 2010. The grid of 175 cameras is located across the wooded and plains areas of the Serengeti, and provides opportunities to study animal behavior and interactions.
Snapshot South Africa (MLP) (South Africa)
Molopo Game Reserve is located along the Botswanan border with South Africa in the latter's North West Province and, owing to the relative scarcity of large predators in the area, is one of the few walkable protected areas in the nation.
Snapshot Tswalu (TSW) (South Africa)
Located in the eastern Kalahari bushveld of the Northern Cape province, Tswalu Kalahari Reserve is the largest privately-owned protected area in South Africa. The wildlife assemblage includes many cryptic animals such as pangolin, aardvark, and brown hyena.
Other useful links
MegaDetector results for all camera trap datasets on LILA are available here.
Information about mapping camera trap datasets to a common taxonomy is available here.

Seattle(ish) Camera Traps
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/seattleish-camera-traps
Overview
I'm breaking the fourth wall right from the start here: this dataset comes from my house, and is intended to fill some specific gaps in public camera trap data that are difficult to fill from "real" camera trap data. In particular, the following things are important to developing and testing AI models for camera traps, but are largely missing from public camera trap data (at least as of December 2024):
- Images of humans (which are excluded from all public sources I'm aware of, including LILA, because consent is complicated when it comes to camera traps)
- Images from consumer-grade camera traps (because the intersection between "people who curate large datasets for public release" and "people who are content to entrust their data collection to a $50 camera from Amazon that stops working in a light fog" is... small). But these cameras are increasingly common, and they're different (they generally provide lower image quality than research-grade cameras, and are consequently more difficult for AI).
- Video, especially intact, full-size videos (as opposed to sequences of frames sampled from videos, or videos reduced to thumbnail size) (because camera trap video is still a growing phenomenon)
So, as something between "a test data set", "a random hobby project", and “an attempt to make stone soup”, I'm releasing this dataset containing ~20k images (in ~6.7k sequences) and ~4.5k videos from my yard in the Seattle area. Images and videos containing any people other than me have been removed, which is why I don't use the label "human", I use the label "dan" (although AFAIK I am human). Audio has been removed from all the videos. The most common labels are "empty" (16,779 instances), "dan" (2,484 instances), "coyote" (1,566 instances), "squirrel" (1,340 instances), and "dog" (638 instances).
Speaking of which, is this all just a really complicated excuse to post pictures of my dog on the Internet? Maybe. Maybe it is.
Given that there is just one human in the data, this dataset is unlikely to be useful for training models for recognizing humans, but I hope it's useful for basic infrastructure testing... i.e., does my code do something reasonable when humans are present in images/video? That kind of basic testing has historically been surprisingly difficult.
And speaking of stone soup... if we do want to get to a more diverse collection of human images, it would be great if other camera trap folks were interested in contributing! If we are the subjects, we can consent to being included, and we can help unlock this important aspect of training data that has historically been very difficult to get into the public domain (for good reason). In other words, I'd like to see this dataset grow from "Seattle-ish Camera Traps" to "Camera Trappers in Camera Traps". If you have data that you're interested in contributing, email me!
About dates and times in this data set
The absolute dates and times are totally meaningless in this dataset... I suspect this is also a common feature in consumer-grade camera traps, where it's much less likely that anyone bothers to set the time/date correctly. However, the top-level "check date" folders are meaningful (so you could, for example, ask whether more animals visited my neighborhood during COVID), and the times/dates within a "check date" folder are meaningful in a relative sense, so the division of images into sequences should be reliable.
Citation, license, and contact information
For questions about this data set, contact Dan Morris.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in a zipfile (150GB), and unzipped images are available in the following cloud storage folders:
- gs://public-datasets-lila/seattleish-camera-traps (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/seattleish-camera-traps (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/seattleish-camera-traps (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download individual images via http, you can. For example, the thumbnail below appears in the metadata as:
camera_trap_images/2023.04.26/location-06/dan_and_dog/IMG_0010.JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
Information about mapping camera trap datasets to a common taxonomy is available here.

UNSW Predators
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/unsw-predators
Overview
This dataset contains 131,802 images from 82 camera locations in New South Wales, Australia. Labels are provided for five categories: dingo (24,540 images), fox (4,421 images), goanna (84,361 images), possum (2,074 images), and quoll (16,406 images). No blank images are included.
Images were collected by Brendan Alting through the Myall Lakes Dingo/Dapin Project on Browning Strike Force HD Pro cameras deployed from December 2022 to March 2023 near trails in Myall Lakes National Park, New South Wales. Cameras were positioned approximately two metres away from a PVC pipe containing 200g of inaccessible raw chicken necks, staked into the ground in front of a large log to encourage quolls to walk across the log and present both flanks to the camera. Lures were replaced at each site six times during the survey (every 9-22 days; mean 16 days). Baited cameras were loosely arranged in clusters of three, with each cluster (N=13) spaced 4502 metres apart (range 2510m-6756m), and cameras within clusters were spaced on average 1100m apart (range 495m-1483m). Baited cameras were deployed for 90 days and set to capture three images per sequence, at high sensitivity with a 1s delay.
Data collection was funded by the Oatley Flora and Fauna Society, the Australian Wildlife Society, Taronga Conservation Society Australia, and a UNSW Research Technology Services (ResTech) AWS cloud grant. Work was conducted under approval 22/102A from the UNSW Animal Ethics Committee.
Citation, license, and contact information
For questions about this data set, contact Neil Jordan.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations (including species tags and unique location identifiers) are provided in COCO Camera Traps format.
For information about mapping this dataset's categories to a common taxonomy, see this page.
Downloading the data
Metadata is available here.
Images are available in the following cloud storage folders:
- gs://public-datasets-lila/unsw-predators/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/unsw-predators/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/unsw-predators/images (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download individual images via http, you can. For example, the thumbnail below appears in the metadata as:
BrendanAltingMLDP2023Images/Q15/Q15__2022-12-21__05-26-18(33).JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
.JPG){kind=link}
.JPG){kind=link}
.JPG){kind=link}
Having trouble downloading? Check out our FAQ.
Other useful links
Information about mapping camera trap datasets to a common taxonomy is available here.

Non-camera-trap datasets
Chesapeake Land Cover
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/lcmcvpr2019
Overview
This dataset contains high-resolution aerial imagery from the USDA NAIP program [1], high-resolution land cover labels from the Chesapeake Conservancy [2], low-resolution land cover labels from the USGS NLCD 2011 dataset [3], low-resolution multi-spectral imagery from Landsat 8 [4], and high-resolution building footprint masks from Microsoft Bing [5], formatted to accelerate machine learning research into land cover mapping. The Chesapeake Conservancy spent over 10 months and $1.3 million creating a consistent six-class land cover dataset covering the Chesapeake Bay watershed. While the purpose of the mapping effort by the Chesapeake Conservancy was to create land cover data to be used in conservation efforts, the same data can be used to train machine learning models that can be applied over even wider areas. The organization of this dataset (detailed below) will allow users to easily test questions related to this problem of geographic generalization, i.e. how to train machine learning models that can be applied over even wider areas. For example, this dataset can be used to directly estimate how well a model trained on data from Maryland can generalize over the remainder of the Chesapeake Bay. Python code for training and testing deep learning models (Keras/TensorFlow based) can be found in the accompanying GitHub repository:
https://github.com/calebrob6/land-cover
Further developments in models and related tools can be found at:
https://github.com/Microsoft/landcover
Papers using a superset of this data include [6, 7]. Paper [8] uses data from the same sources.
Citation
If you use this data set, please cite the associated manuscript:
Robinson C, Hou L, Malkin K, Soobitsky R, Czawlytko J, Dilkina B, Jojic N. Large Scale High-Resolution Land Cover Mapping with Multi-Resolution Data. Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition (CVPR 2019). (bibtex)
Dataset organization
Tiles
This dataset is organized into non-overlapping tiles. A tile is a spatial area measuring roughly 6km x 7.5km (with definitions that roughly match up with USGS quarter quadrangles). Each tile comes with seven corresponding GeoTIFFs:
- NAIP 2013/2014 imagery ("_naip-new.tif" suffix)
- NAIP 2011/2012 imagery ("_naip-old.tif" suffix)
- Chesapeake Conservancy land cover labels ("_lc.tif" suffix)
- NLCD 2011 labels ("_nlcd.tif" suffix)
- Landsat 8 leaf-on composite ("_landsat-leaf-on.tif" suffix)
- Landsat 8 leaf-off composite ("_landsat-leaf-off.tif" suffix)
- Building footprint mask ("_buildings.tif" suffix)
These GeoTIFFs are all aligned and at a 1m spatial resolution. Here, the low-resolution NLCD labels (natively at a 30m spatial resolution) have been reprojected to 1m with nearest-neighbor upsampling, while the NAIP and high-resolution land cover labels are natively aligned at 1m. The Landsat 8 leaf-on and leaf-off composites are created from the median of the non-cloudy T1 surface reflectance pixels between April 1-September 30 and October 1st-March 31 in the years 2013-2017 respectively. The final composites are upsampled to 1m spatial resolution. Finally, the building footprints have been rasterized to a 1m resolution from their native polygon format, also with nearest-neighbor sampling. There are 732 total tiles, 125 sampled uniformly from each of the following (state, year) pairs:
- Delaware 2013 (only 107 tiles)
- New York 2013
- Maryland 2013
- Pennsylvania 2013
- West Virginia 2014
- Virginia 2014
The ~125 tiles from each (state, year) pair are further split into 100 "train tiles" (except for Delaware, which has 82 train tiles), 5 "validation tiles", and 20 "test tiles". The tiles corresponding to each split can be found in different directories. For example, the train/val/test splits for West Virginia can be found in the following three subdirectories, respectively:
- wv_1m_2014_extended-debuffered-train_tiles/
- wv_1m_2014_extended-debuffered-val_tiles/
- wv_1m_2014_extended-debuffered-test_tiles/
Data description
The contents of each type of data layer are as follows:
- NAIP - Four-channel rasters that contain the R, G, B, and NIR bands respectively. Values are uint8s.
- Landsat 8 - Nine-channel rasters that contain the B1, B2, B3, B4, B5, B6, B7, B10, and B11 bands from a median mosaic of Landsat 8 surface reflectance imagery. The bands are described here. Values are float32.
- Chesapeake Conservancy land cover labels - Single-channel rasters that contain high-resolution land cover labels from this dataset. The values are uint8s with the following mapping:
- 1 = water
- 2 = tree canopy / forest
- 3 = low vegetation / field
- 4 = barren land
- 5 = impervious (other)
- 6 = impervious (road)
- 15 = no data
- NLCD labels - Single-channel rasters with values that match those described here. The values of 0 and 255 indicate no data.
- Building footprint labels - Single-channel rasters with a binary mask generated from the Bing Building Footprints dataset.
Spatial index
This dataset includes a "spatial_index.geojson" file that contains the boundaries of each tile in the dataset in the EPSG:3857 projection with attributes indicating which split the tile is in as well as attributes that include the filename pointer for each layer of data (e.g. "naip-new", "naip-old", "nlcd", ...).
Download links
A zipfile of the dataset is available at the following locations: cvpr_chesapeake_landcover.zip (GCP link, 140GB)
cvpr_chesapeake_landcover.zip (AWS link, 140GB)
cvpr_chesapeake_landcover.zip (Azure link, 140GB) The MD5 checksum of the zip file is 0ea5e7cb861be3fb8a06fedaaaf91af9 . Data is already unzipped and available in the following cloud storage folders; see LILA's direct image access guide for download instructions.
- gs://public-datasets-lila/lcmcvpr2019/cvpr_chesapeake_landcover (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/lcmcvpr2019/cvpr_chesapeake_landcover (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/lcmcvpr2019/cvpr_chesapeake_landcover (Azure)
Having trouble downloading? Check out our FAQ.
Contact
For questions about this dataset, contact calebrob6+lcmcvpr2019@gmail.com.
Licensing
Labels The organizations responsible for generating and funding this dataset make no representations of any kind including, but not limited to the warranties of merchantability or fitness for a particular use, nor are any such warranties to be implied with respect to the data. Although every effort has been made to ensure the accuracy of information, errors may be reflected in data supplied. The user must be aware of data conditions and bear responsibility for the appropriate use of the information with respect to possible errors, original map scale, collection methodology, currency of data, and other conditions. Credit should always be given to the data source when this data is transferred, altered, or used for analysis. Images Landsat and NAIP imagery has been released into the public domain. License information about NAIP and Landsat is available here and here, respectively. Building footprints The building footprints are licensed under the Open Data Commons Open Database License (ODbL). License information about Microsoft's US building footprints dataset isavailable here.
References
- United States Department of Agriculture. National Aerial Imagery Program. Online.
- Chesapeake Conservancy. Land cover data project. Online.
- Homer C, Dewitz J, Yang L, Jin S, Danielson P, Xian G, Coulston J, Herold N, Wickham J, Megown K. Completion of the 2011 National Land Cover Database for the conterminous United States – representing a decade of land cover change information. Photogrammetric Engineering & Remote Sensing. May 2015.
- United States Geological Survey. Landsat 8. Online.
- Microsoft. US Building Footprints. Online.
- Malkin K, Robinson C, Hou L, Soobitsky R, Czawlytko J, Samaras D, Saltz J, Joppa L, Jojic N. Label super-resolution networks. International Conference on Learning Representations (ICLR). 2019.
- Robinson C, Hou L, Malkin K, Soobitsky R, Czawlytko J, Dilkina B, Jojic N. Large Scale High-Resolution Land Cover Mapping with Multi-Resolution Data. Computer Vision and Pattern Recognition (CVPR). 2019.
- Robinson C, Ortiz A, Malkin K, Elias B, Peng A, Morris D, Dilkina B, Jojic N. Human-Machine Collaboration for Fast Land Cover Mapping. arXiv 1096.04176, June 2019.
Amur Tiger Re-identification
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/cvwc2019
Overview
This dataset contains more than 8,000 video clips of 92 individual Amur tigers from 10 zoos in China. Around 9500 bounding boxes are provided along with pose keypoints, and around 3600 of those bounding boxes are associated with an individual tiger ID. This data set was originally published as part of the Re-identification challenge at the ICCV 2019 Workshop on Computer Vision for Wildlife Conservation; suggested train/val/test splits correspond to those used for the competition.
Data access
GCP links
| Data type | Split | Images | Annotations |
|---|---|---|---|
| Detection | train | Detection train images (2GB) | Detection train annotations |
| test | Detection test images (1.4GB) | ||
| Pose | train | Pose train images (255MB)Pose val images (38MB) | Pose train/val annotations |
| test | Pose test images (70MB) | ||
| Re-identification | train | Re-ID train images (132MB) | Re-ID train annotations |
| test | Re-ID test images (90MB) | Re-ID test annotations |
Azure links
| Data type | Split | Images | Annotations |
|---|---|---|---|
| Detection | train | Detection train images (2GB) | Detection train annotations |
| test | Detection test images (1.4GB) | ||
| Pose | train | Pose train images (255MB)Pose val images (38MB) | Pose train/val annotations |
| test | Pose test images (70MB) | ||
| Re-identification | train | Re-ID train images (132MB) | Re-ID train annotations |
| test | Re-ID test images (90MB) | Re-ID test annotations |
AWS links
| Data type | Split | Images | Annotations |
|---|---|---|---|
| Detection | train | Detection train images (2GB) | Detection train annotations |
| test | Detection test images (1.4GB) | ||
| Pose | train | Pose train images (255MB)Pose val images (38MB) | Pose train/val annotations |
| test | Pose test images (70MB) | ||
| Re-identification | train | Re-ID train images (132MB) | Re-ID train annotations |
| test | Re-ID test images (90MB) | Re-ID test annotations |
Having trouble downloading? Check out our FAQ.
Data format
All annotation tar files include README.md files with detailed format information; this section provides a high-level summary only.
Detection
Bounding boxes are provided in Pascal VOC format.
Pose
Pose annotations are provided in COCO format. Annotations use the COCO "keypoint" annotation type, with categories like "left_ear", "right_ear", "nose", etc.
Re-identification
Identifications in the "train" set are provided as a .csv-formatted list of [ID,filename] pairs; the "test" set contains only a list of images requiring identification. Pose annotations are provided for both sets.
The competition for which this dataset was prepared divided re-identification into two tasks, one ("plain re-ID") where pose and bounding box annotations were available, and one ("wild re-ID") where annotations were not available.
Licensing
This data set is released under the CC BY-NC-SA 4.0 License. Images are owned by MakerCollider and the World Wildlife Fund.
Citation
If you use this dataset, please cite the associated arXiv publication:
Li, S., Li, J., Lin, W., & Tang, H. (2019). Amur Tiger Re-identification in the Wild. arXiv preprint arXiv:1906.05586.
Contact
For questions about this data set, contact cvwc2019@hotmail.com.

Conservation Drones
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/conservationdrones
Overview
Monitoring of protected areas to curb illegal activities like poaching is a monumental task. Real-time data acquisition has become easier with advances in unmanned aerial vehicles (UAVs) and sensors like TIR cameras, which allow surveillance at night when poaching typically occurs. However, it is still a challenge to accurately and quickly process large amounts of the resulting TIR data. The Benchmarking IR Dataset for Surveillance with Aerial Intelligence (BIRDSAI, pronounced "bird's-eye") is a long-wave thermal infrared (TIR) dataset containing nighttime images of animals and humans in Southern Africa. The dataset allows for testing of automatic detection and tracking of humans and animals with both real and synthetic videos, in order to protect animals in the real world.
There are 48 real aerial TIR videos and 124 synthetic aerial TIR videos (generated with AirSim), for a total of 62k and 100k images, respectively. Tracking information is provided for each of the animals and humans in these videos. We break these into labels of animals or humans, and also provide species information when possible, including for elephants, lions, and giraffes. We also provide information about noise and occlusion for each bounding box.
Data layout
In the training set that is provided, there are two folders, one for simulated data (TrainSimulation), one for real data (TrainReal). Each of these folders contains folders for the annotation .csv files for each video (annotations) and the individual .jpg frames in each video (images).
In the "images" folder in "TrainSimulation", there are folders for each video; in addition to the .jpg infrared images, these zip files also contain infrared .png, RGB, and segmentation images provided by AirSim. We include in "TrainSimulation/annotations" two files containing the infrared digital counts for the different objects in the scene for both winter and summer. These, combined with the infrared simulation .png files, allow you to search for different objects in the images, if you're looking for further information than is provided in the annotation .csv files.
The test set contains a single folder called "TestReal", which follows the same pattern as "TrainReal".
Annotation format
We follow the MOT annotation format, which is a .csv file with the following columns:
[frame_number], [object_id], [x], [y], [w], [h], [class], [species], [occlusion], [noise]
- class: 0 if animals, 1 if humans
- species: -1: unknown, 0: human, 1: elephant, 2: lion, 3: giraffe, 4: dog, 5: crocodile, 6: hippo, 7: zebra, 8: rhino. 3 and 4 occur only in real data. 5, 6, 7, 8 occur only in synthetic data.
- occlusion: 0 if there is no occlusion, 1 if there is an occlusion (i.e., either occluding or occluded) (note: intersection over union threshold of 0.3 used to assign occlusion; more details in paper)
- noise: 0 if there is no noise, 1 if there is noise (note: noise labels were interpolated from object locations in previous and next frames; for more than 4 consecutive frames without labels, no noise labels were included; more details in paper)
Within the "TrainReal/annotations" folders, we include a file called "water_metadata....txt", which contains has the names of videos that contain water. The same is found in "TestReal/annotations".
Although "annotations" can be used for single- and multi-object tracking, we have included within "TrainReal/annotations" the exact training sequences and splits used in our single-object tracking experiments under "tracking". The same is included in "TestReal/annotations/tracking".
Helper code and a README is provided at github.com/exb7900/BIRDSAI to give more detail on how to use these sequences.
Downloading the data
Unzipped data
Data is already unzipped and available in the following cloud storage folders; see LILA's direct image access guide for download instructions.
Google Cloud Storage folders
gs://public-datasets-lila/conservationdrones/v01/TrainReal
gs://public-datasets-lila/conservationdrones/v01/TrainSimulation
gs://public-datasets-lila/conservationdrones/v01/conservationdrones-testset/TestReal
AWS S3 folders
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/conservationdrones/v01/TrainReal
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/conservationdrones/v01/TrainSimulation
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/conservationdrones/v01/conservationdrones-testset/TestReal
Azure Blob Storage folders
https://lilawildlife.blob.core.windows.net/lila-wildlife/conservationdrones/v01/TrainReal
https://lilawildlife.blob.core.windows.net/lila-wildlife/conservationdrones/v01/TrainSimulation
https://lilawildlife.blob.core.windows.net/lila-wildlife/conservationdrones-testset/TestReal
Big zipfiles
You can also download the archive in three zipfiles (for real training data, simulated training data, and real test data).
GCP links
conservation_drones_train_real.zip (2.1GB)
conservation_drones_train_simulation.zip (39.5GB)
conservation_drones_test_real.zip (1.6GB)
AWS links
conservation_drones_train_real.zip (2.1GB)
conservation_drones_train_simulation.zip (39.5GB)
conservation_drones_test_real.zip (1.6GB)
Azure links
conservation_drones_train_real.zip (2.1GB)
conservation_drones_train_simulation.zip (39.5GB)
conservation_drones_test_real.zip (1.6GB)
Challenges
This dataset was used as the basis for the ICVGIP Visual Data Challenge at ICVGIP 2020.
Having trouble downloading?
Check out our FAQ.
License, citation, and acknowledgements
This dataset is released under the Community Data License Agreement (permissive variant).
If you use this dataset, please consider citing our paper:
Bondi E, Jain R, Aggrawal P, Anand S, Hannaford R, Kapoor A, Piavis J, Shah S, Joppa L, Dilkina B, Tambe M. BIRDSAI: A Dataset for Detection and Tracking in Aerial Thermal Infrared Videos. (bibtex)
For questions about this dataset, contact Elizabeth Bondi at Harvard University (ebondi@g.harvard.edu).
This work was supported by Microsoft AI for Earth, NSF grants CCF-1522054 and IIS-1850477, MURI W911NF-17-1-0370, and the Infosys Center for Artificial Intelligence, IIIT-Delhi. We also thank the labeling team.
[video src="https://lilawildlife.blob.core.windows.net/lila-wildlife/conservationdrones/conservation_drones_0000000367_0000000000.mp4" poster="https://lilawildlife.blob.core.windows.net/lila-wildlife/conservationdrones/conservation_drones_0000000367_0000000000.jpg"]
{kind=link}
Forest Canopy Height in Mexican Ecosystems
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/boise-state-vegetation
Overview
Airborne light detection and ranging (lidar) data have great potential to map vegetation structure at a fine resolution, including estimating carbon stocks, canopy closure, and tree height. While airborne-lidar-derived vegetation structural measurements could play an important role in ecological restoration monitoring, these data are limited to only a tiny fraction of the Earth’s surface. Data fusion to combine high-resolution lidar data with medium resolution satellite data (such as Landsat imagery) represents one way to extend the spatial and temporal reach of airborne data.
This data set includes 1,105 aerial images captured over Mexico as part of the NASA G-LiHT program, along with lidar-derived canopy height values and Landsat-derived vegetation indices for 499,925 sample points within those images.
The associated open-source repo provides tools required to replicate this sampling methodology.
Data format
G-LiHT images are in GeoTIFF format.
Annotations are provided in a .csv file with 499925 rows, each representing one sample, and 12 columns:
- EVI: Landsat-derived enhanced vegetation index
- NVDI: Landsat-derived normalized difference vegetation index
- NDWI: Landsat-derived normalized difference water index
- NBR: Landsat-derived normalized burn ratio
- CanopyHeig: lidar-derived canopy height in meters
- Ecoregion: Ecoregion label, e.g. "Tropical and Subtropical Coniferous Forests"
- ID_G_LiTH_: G-LiHT ID image; corresponds to the filenames in the "Images" folder
- ID_Landsat: Unique ID for each Landsat pixel
- X: longitude
- Y: latitude
- Vegetation: vegetation type extracted from the Mexican National Institute of Statistics and Geography (INEGI), e.g. "AGRICULTURA DE TEMPORAL ANUAL"
- field_1: field identifier (a unique row identifier)
Citation
If you use these data in a publication or report, please use the following citation:
Requena-Mullor JM, Caughlin TT. Lidar-derived canopy height data and Landsat-derived vegetation indices for the G-LiHT NASA acquisitions in Mexico. Dataset.
Contact information
For questions about this data set, contact Juan Miguel Requena Mullor (juanmimullor@gmail.com).
License
G-LiHT images are released according to NASA's Data and Information Policy.
The .csv file containing canopy height and vegetation information is released under the Community Data License Agreement (permissive variant).
Download links
Metadata (GCP link, 21MB)
Metadata (Azure link, 21MB)
Metadata (AWS link, 21MB)
Images (62.9GB) are available in the following cloud storage folders; see LILA's direct image access guide for download instructions.
- gs://public-datasets-lila/boise-state-vegetation/tifImages (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/boise-state-vegetation/tifImages (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/boise-state-vegetation/tifImages (Azure)
Having trouble downloading? Check out our FAQ.
Adirondack Research Invasive Species Mapping
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/adkres-invasive
Overview
This data set contains interpolated lake characteristics data of twelve lakes, including depth, substrate hardness, and vegetation presence. These data can be useful for calculating the probability of occurrence of other biological organisms that have habitat preferences related to water depth and substrate. More information about the survey methodology is available here.
Citation, license, and contact information
For questions about this data set, contact Ezra Schwartzberg at Adirondack Research.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations are provided in .csv format, with the following columns:
- Distance_from_shore (feet)
- Depth (feet)
- Bottom_Hardness (relative units)
- Vegetation (relative units, indicating vegetation height)
- Longitude
- Latitude
- Lake_Name
- County
- Township
- Date_surveyed
- AIS_Species (name of invasive species present, if any)
- AIS_Density (relative units)
Downloading the data
Data download links:
Download from GCP (155MB)
Download from AWS (155MB)
Download from Azure (155MB)
Having trouble downloading? Check out our FAQ.
Whale Shark ID
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wild-me/whaleshark.coco.tar.gz
Overview
This data set contains images of whale sharks (Rhincodon typus) with bounding boxes and individual animal identifications. This dataset represents a collaborative effort based on the data collection and population modeling efforts conducted at Ningaloo Marine Park in Western Australia from 1995-2008. Photos (7888) and metadata from 2441 whale shark encounters were collected from 464 individual contributors, especially from the original research of Brad Norman and from members of the local whale shark tourism industry who sight these animals annually from April-June. Images were annotated with bounding boxes around each visible whale shark and viewpoints were labeled (e.g., left, right, etc.). A total of 543 individual whale sharks were identified by their unique spot patterning using first computer-assisted spot pattern recognition (Arzoumanian et al.) and then manual review and confirmation. A total of 7,693 named sightings were exported.
Data format
The dataset is released in the Microsoft COCO format and therefore uses flat image folders with associated YAML metadata files. We have collapsed the entire dataset into a single "train" label and have left "val" and "test" empty; we do this as an invitation to researchers to experiment with their own novel approaches for dealing with the unbalanced and chaotic distribution on the number of sightings per individual. All of the images in the dataset have been resized to have a maximum dimension of 3,000 pixels. The metadata for all animal sightings is defined by an axis-aligned bounding box and includes information on the rotation of the box (theta), the viewpoint of the animal, a species (category) ID, a source image ID, an individual string ID name, and other miscellaneous values. The temporal ordering of the images, and an anonymized ID for the original photographer, can be determined from the metadata for each image.
Citation, license, and contact information
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
If you use this dataset in published work, please cite as:
Holmberg J, Norman B, Arzoumanian Z. Estimating population size, structure, and residency time for whale sharks Rhincodon typus through collaborative photo-identification. Endangered Species Research. 2009 Apr 8;7(1):39-53.
Downloading the data
Data download link:
Images and metadata (GCP link) (6GB)
Images and metadata (Azure link) (6GB)
Images and metadata (AWS link) (6GB)
Having trouble downloading? Check out our FAQ.
![]()
Great Zebra and Giraffe Count and ID
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wild-me/gzgc.coco.tar.gz
Overview
This dataset contains images of plains zebra (Equus quagga) and Masai giraffe (Giraffa tippelskirchi) with bounding boxes and individual animal identifications. Images are taken from a two-day census of Nairobi National Park, located just south of the airport in Nairobi, Kenya. The “Great Zebra and Giraffe Count” (GZGC) photographic census was organized on February 28th and March 1st 2015 and had the participation of 27 different teams of citizen scientists and 55 total photographers. Only images containing either zebras or giraffes were included in this dataset, for a total of 4,948 images. All images are labeled with bounding boxes around the individual animals for which there is ID metadata, meaning some images contain missing boxes and are not intended to be used for object detection training or testing. Viewpoints for all animal annotations were also added. All ID assignments were completed using the HotSpotter algorithm (Crall et al. 2013) by visually matching the stripes and spots as seen on the body of the animal. A total of 2,056 combined names are released for 6,286 individual zebra and 639 giraffe sightings. This dataset presents as a challenging comparison compared to the whale shark dataset since it contains a significantly higher number of animals that are only seen once during the survey.
Data format
The dataset is released in the Microsoft COCO .json format. We have collapsed the entire dataset into a single "train" label and have left "val" and "test" empty; we do this as an invitation to researchers to experiment with their own novel approaches for dealing with the unbalanced and chaotic distribution on the number of sightings per individual. All of the images in the dataset have been resized to have a maximum dimension of 3,000 pixels. The metadata for all animal sightings is defined by an axis-aligned bounding box and includes information on the rotation of the box (theta), the viewpoint of the animal, a species (category) ID, a source image ID, an individual string ID name, and other miscellaneous values. The temporal ordering of the images, and an anonymized ID for the original photographer, can be determined from the metadata for each image.
Citation, license, and contact information
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
If you use this dataset in published work, please cite as:
Parham J, Crall J, Stewart C, Berger-Wolf T, Rubenstein DI. Animal population censusing at scale with citizen science and photographic identification. In AAAI Spring Symposium-Technical Report 2017 Jan 1.
Downloading the data
Data download links:
Images and metadata (GCP link) 10GB)
Images and metadata (Azure link) (10GB)
Images and metadata (AWS link) (10GB)
Having trouble downloading? Check out our FAQ.
![]()
HKH Glacier Mapping
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/icimod-glacier-mapping
Overview
The Hindu Kush Himalayas (HKH) glacier mapping dataset includes imagery of the Hindu Kush Himalayas (HKH) region, along with polygons indicating the locations of glaciers. This dataset is intended to facilitate the training of models that can identify glaciers in remotely-sensed imagery.
The HKH is also known as the world’s “Third Pole”, as it consists of one of the largest concentrations of snow and ice besides the two poles. It constitutes more than four million square kilometers of hills and mountains in the eight countries of Afghanistan, Bangladesh, Bhutan, China, India, Myanmar, Nepal, and Pakistan. Glaciers within this region have been identified and classified by experts at the International Centre for Integrated Mountain Development (ICIMOD).
This dataset couples those annotated glacier locations with multispectral imagery from Landsat 7 [1] and digital elevation and slope data from SRTM [2]. Imagery are provided as thirty-five Landsat tiles and 14,190 extracted numpy patches. Labels are available as raw vector data in shapefile format and as multichannel numpy masks. Both the labels and the masks are cropped according to the borders of the HKH region.
Python code for training and testing machine learning models using PyTorch, as well as the source for a glacier mapping web tool, can be found in the accompanying GitHub repository:
https://github.com/krisrs1128/glacier_mapping
Dataset organization
Tiles
At the highest level, this dataset is organized by tiles. A tile is a spatial area measuring roughly 6km x 7.5km (with definitions that roughly match up with USGS quarter quadrangles). Each tile comes with one corresponding GeoTIFF file. The entire glacier mapping dataset contains 35 tiles from Afghanistan, Bangladesh, Bhutan, China, India, Myanmar, Nepal, and Pakistan.
Each GeoTIFF tile consists of 15 channels:
- LE7 B1 (blue)
- LE7 B2 (green)
- LE7 B3 (red)
- LE7 B4 (near infrared)
- LE7 B5 (shortwave infrared 1)
- LE7 B6_VCID_1 (low-gain thermal infrared)
- LE7 B6_VCID_2 (high-gain thermal infrared)
- LE7 B7 (shortwave infrared 2)
- LE7 B8 (panchromatic)
- LE7 BQA (quality bitmask)
- NDVI (vegetation index)
- NDSI (snow index)
- NDWI (water index)
- SRTM 90 elevation
- SRTM 90 slope
These data were acquired from Google Earth Engine’s LE7 and SRTM collections using this script.
All channels are aligned at 30m spatial resolution. Elevation and slope channels were upsampled from 90m to 30m resolution.
Glacier annotations
Digital polygon data indicating the status of glaciers in the HKH region from 2002 to 2008 were provided by ICIMOD [3].
Patches
We also provide 14190 numpy patches. The numpy patches are all of size 512 x 512 x 15 and corresponding 512 x 512 x 2 pixel-wise mask labels; the two channels in the pixel-wise masks correspond to clean-iced and debris-covered glaciers. Patches’ geolocation information, time stamps, source Landsat IDs, and glacier density are available in a geojson metadata file. We show an example of the metadata below:
"type": "Feature", "properties": "img_source": "/datadrive/glaciers/unique_tiles/LE07_149037_20041024.tif", "mask_source": "/datadrive/glaciers/processed_exper/masks/mask_00.npy", "img_slice": "/datadrive/glaciers/processed_exper/slices/slice_0_img_003.npy", "mask_slice": "/datadrive/glaciers/processed_exper/slices/slice_0_mask_003.npy", "mask_mean_0": 0.0, "mask_mean_1": 0.0, "mask_mean_2": 0.0, "img_mean": 189.76698303222656 , "geometry": "type": "Polygon", "coordinates": [ [ [ 386932.71929824561812, 3564585.0 ], [ 386932.71929824561812, 3579767.12783851986751 ], [ 371750.78947368421359, 3579767.12783851986751 ], [ 371750.78947368421359, 3564585.0 ], [ 386932.71929824561812, 3564585.0 ] ] ]
Download links
All data (patches, polygons, images) (GCP link) (29.4GB)
All data (patches, polygons, images) (Azure link) (29.4GB)
All data (patches, polygons, images) (AWS link) (29.4GB)
Having trouble downloading? Check out our FAQ.
Citation and contact information
For questions about this dataset, contact anthony.ortiz@microsoft.com or [ksankaran@wisc.edu](mailto: ksankaran@wisc.edu).
If you use this dataset, please cite:
Baraka S, Akera B, Aryal B, Sherpa T, Shresta F, Ortiz A, Sankaran K, Lavista Ferres J, Matin M, Bengio Y. 2020. Machine Learning for Glacier Monitoring in the Hindu Kush Himalaya. NeurIPS 2020 Climate Change AI Workshop (2020).
License
Annotations
Annotations are released under the Community Data License Agreement (permissive variant).
Images
Landsat and SRTM data have been released into the public domain. License information about SRTM and Landsat is available here and here, respectively.
References
- United States Geological Survey. Landsat 7. Online
- SRTM 90m DEM Digital Elevation Database. Online
- Bajracharya, S. R., & Shrestha, B. R. (2011). The status of glaciers in the Hindu Kush-Himalayan region. International Centre for Integrated Mountain Development (ICIMOD). Online

Aerial Seabirds West Africa
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/aerial-birds-west-africa
Overview
This dataset contains high-resolution aerial RGB imagery obtained from a census of breeding seabirds in West Africa in 2019. The data was collected as part of a census of breeding seabirds along the West African coast where UAVs were used to map colonies.
The dataset consists of an orthomosaic covering a sandy island with colonies of the focal species breeding royal terns (Thalasseus maximus albididorsalis), Caspian terns (Hydroprogne caspia) and gray-headed gulls (Chroicocephalus cirrocephalus). The orthomosaic also contains great cormorants (Phalacrocorax carbo), great white pelicans (Pelecanus onocrotalus), slender-billed gulls (Chroicocephalus genei), and a number of birds that could not be identified. The individual birds are identified with point annotations, totaling 21,516 annotations.
The data were used to develop a detector using deep Convolutional Neural Networks (CNNs). The description of the model and the results are in a paper that is currently under review (see below). In the paper we focused on three focal species and the other species are lumped and labeled "unknown". The data provided here is the fully annotated test data set and the set as it was used in the paper.
Citation
If you use this data set, please cite the associated manuscript:
Kellenberger B, Veen T, Folmer E, Tuia D. 21,000 birds in 4.5 h: efficient large‐scale seabird detection with machine learning. Remote Sensing in Ecology and Conservation. 2021.
Data format
The dataset consists of:
- The orthomosaic is a RGB GeoTIFF with ground resolution ~1 cm. The coordinate reference system is WGS 84 / UTM zone 28N; to avoid possible abuse of the data and disturbance of the breeding site, the spatial reference is changed by translating the file to origin (0,0). The internal spatial reference remains intact so that the distances and sizes of the birds are correct. (seabirds_rgb.tif)
- A .csv file with (translated) point coordinates and the labels of all species. (labels_birds_full.csv)
- A .csv file with point coordinates and the labels of the target species that were used in the paper. (labels_birds_paper.csv)
Download links
GCP download links
Orthomosaic (.tif) (2.2GB)
Annotated points (all) (.csv) (1.3MB)
Annotated points (paper subset) (.csv) (1.3MB)
GeoPackage (.gpkg) (5.3MB)
Azure download links
Orthomosaic (.tif) (2.2GB)
Annotated points (all) (.csv) (1.3MB)
Annotated points (paper subset) (.csv) (1.3MB)
GeoPackage (.gpkg) (5.3MB)
AWS download links
Orthomosaic (.tif) (2.2GB)
Annotated points (all) (.csv) (1.3MB)
Annotated points (paper subset) (.csv) (1.3MB)
GeoPackage (.gpkg) (5.3MB)
Having trouble downloading? Check out our FAQ.
Contact information
For questions about this dataset, contact Eelke Folmer.
License
Image and annotations are released under the Community Data License Agreement (permissive variant).

GeoLifeCLEF 2020
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/geolifeclef-2020
Overview
Understanding the geographic distribution of species is a key concern in conservation. By pairing species occurrences with environmental features, researchers can model the relationship between an environment and the species which may be found there. To facilitate research in this area, we present the GeoLifeCLEF 2020 (GLC2020) dataset, which consists of 1.9 million geo-located species observations paired with high-resolution remote sensing imagery, land cover data, and altitude, in addition to traditional low-resolution climate and soil variables. The observations in this dataset cover 31,435 plant and animal species from the United States and France. The dataset was originally prepared for the GeoLifeCLEF 2020 competition. Full details can be found in the dataset paper (cited below).
Citation
If you use this data set, please cite the associated manuscript:
Cole E, Deneu B, Lorieul T, Servajean M, Botella C, Morris D, Jojic N, Bonnet P, Joly A. The GeoLifeCLEF 2020 Dataset. arXiv preprint arXiv:2004.04192. 2020 Apr 8. (bibtex)
Data format
The dataset consists of three components: high-resolution patches, annotations for those patches, and low-resolution covariate rasters.
Each high-resolution patch is stored as a pair of .npy files: XXX.npy containing RGB-IR and land cover (256x256x5 uint8 array) and XXX_alti.npy containing altitude (256x256x1 uint16 array).
Annotations for the high-resolution patches are provided as JSON files that adhere to a modified version of the COCO dataset annotation format. The format is as follows:
"images": [image],
"categories": [category],
"annotations": [annotation]
image
"id": int,
"width": int,
"height": int,
"file_name": str,
"file_name_alti": str,
"lon": float,
"lat": float,
"country": str
category
"id": int,
"gbif_id": int,
"gbif_name": str
annotation
"id": int,
"image_id": int,
"category_id" int
The low-resolution covariate rasters are provided as pairs of .tif files (one for the US and one for France) for each variable. On the competition GitHub page we provide code to extract values for 27 environmental characteristics at any location in the US or France.
Download links
High-resolution-patches (GCP links)
High-resolution patches are available at:
https://storage.googleapis.com/public-datasets-lila/geolifeclef-2020/patches_[region]_[index].tar.gz (11GB each)
...where region is "us" or "fr" for the US and France, respectively, and "index" is 01, 02, ... 20. For example:
https://storage.googleapis.com/public-datasets-lila/geolifeclef-2020/patches_fr_01.tar.gz
High-resolution-patches (AWS links)
High-resolution patches are available at:
...where region is "us" or "fr" for the US and France, respectively, and "index" is 01, 02, ... 20. For example:
High-resolution-patches (Azure links)
High-resolution patches are available at:
https://lilawildlife.blob.core.windows.net/lila-wildlife/geolifeclef-2020/patches_[region]_[index].tar.gz (11GB each)
...where region is "us" or "fr" for the US and France, respectively, and "index" is 01, 02, ... 20. For example:
https://lilawildlife.blob.core.windows.net/lila-wildlife/geolifeclef-2020/patches_fr_01.tar.gz
High-resolution-patches (folder structure)
For each country, each of the 20 .tar.gz files contains five directories from the set 00/, ..., 99/ . For example, patches_fr_01.tar.gz contains 00/, ..., 04/ and patches_fr_02.tar.gz contains 05/, ..., 09/, and so on. Then each of those directories contains subdirectories 00/, ..., 99/. These indices do not have a semantic interpretation, they are just to help the operating system deal with the number of files. Each pair of patch files is named XXXXABCD.npy and XXXXABCD_alti.npy, and lives at CD/AB/ where CD and AB are each among 00/, ..., 99/.
The contents of each file should be extracted to the same directory, such that, for example, the 00/ folder contains the contents of both patches_us_01/ and patches_fr_01/.
Annotations
- Training (450MB) (GCP link) (Azure link) (AWS link)
- Validation (11MB) (GCP link) (Azure link) (AWS link)
- Testing (13MB) (GCP link) (Azure link) (AWS link)
Low-resolution covariate rasters
Covariate rasters (2.4GB) (GCP link) (Azure link) (AWS link)
Having trouble downloading? Check out our FAQ.
Contact information
For questions about this dataset, contact geolifeclef@inria.fr.
License information
RGB-IR imagery
US
Source: NAIP/USGS
License: public domain
FR
Source: IGN
License: CC BY 4.0 (By Permission of IGN)
Land cover
US
Source: NLCD/USGS
License: public domain
FR
Source: CESBIO
License: ODC-BY 1.0
Species occurrences
US
Source: iNaturalist
License: CC BY-NC 4.0
FR
Source #1: Pl@ntNet and iNaturalist
License #1: CC BY 4.0
Source #2: iNaturalist
License #2: CC BY-NC 4.0
Altitude
Source: SRTM/NASA
License: public domain
Soil rasters
Source: SoilGrids
License: CC BY 4.0
Bioclimatic rasters
Source: WorldClim
License: CC BY-SA 4.0
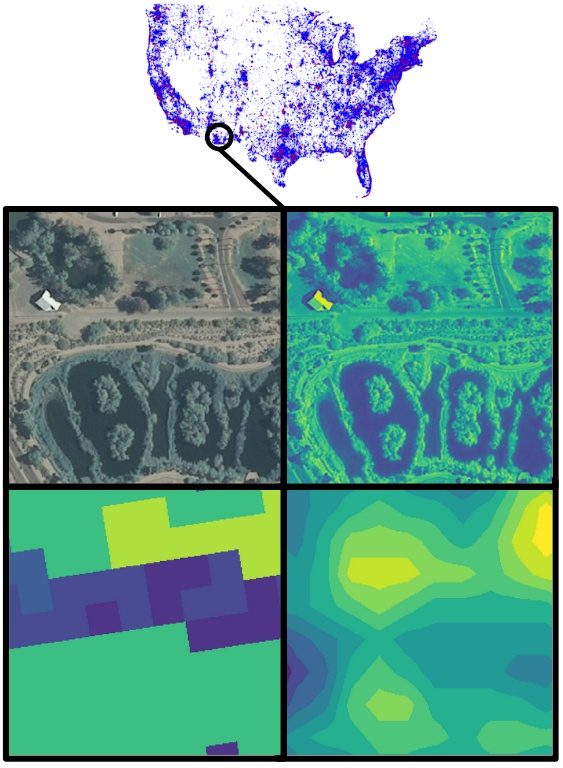
WNI Giraffes
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wni-giraffes
Overview
Masai giraffes are endangered from illegal killing and habitat loss. As part of the world's largest giraffe conservation science project, the Wild Nature Institute has identified thousands of individual Masai giraffes in Tanzania by their unique and unchanging coat patterns. Photogrammetry allows researchers to also track these giraffes' heights and sizes over time from images, by combining keypoint annotations with laser rangefinder data that indicates the distance between the camera and the giraffe.
This dataset contains 29,806 images of giraffes, annotated with keypoints representing four canonical measurement points: the top of the ossicones (horns), the top of the head, the indentation where the neck meets the chest, and the bottom front of the front hoof. Annotations were created by citizen-science volunteers on Zooniverse. Around 40,000 images were annotated in total; this dataset excludes images that were annotated by fewer than five volunteers, and also excludes a test set that can be used in the future to validate algorithms developed based on this dataset to automate keypoint identification.
Data format
Annotations are provided in a .json file, structured as:
"info": [metadata about the data set (version, etc.)],
"annotations": [list of annotations]
annotation
"filename": str,
"id": int,
"collection": str (always "train"),
"keypoints":
'too': [list of keypoints],
'toh': [list of keypoints],
'ni': [list of keypoints],
'fbh': [list of keypoints]
keypoint
"median_x": float,
"median_y": float,
"x": [],
"y": []
Keypoint identifiers have the following interpretations, which are also documented in info['tool_names']:
- too: top of ossicones
- toh: top of head
- ni: neck indent
- fbh: front bottom hoof
x and y contain the raw annotations provided by individual annotators; median_x and median_y are the medians of those values when at least three annotations are present for a specific keypoint. When fewer than three annotations are present for a specific keypoint, median_x and median_y are empty.
Not all keypoints are visible in all images; some images may contain as few as one annotated keypoint (for example, if only the chest of the giraffe is visible).
Sample Python code to read this dataset and plot keypoints (e.g. to produce the thumbnail image at the bottom of this page) is available here.
Citation, license, and contact information
For questions about this dataset, contact Derek Lee (derek@wildnatureinstitute.org) at the Wild Nature Institute.
This dataset is released under the Community Data License Agreement (permissive variant).
Downloading the data
Download images from GCP (196GB)
Download annotations from GCP (8MB)
Download images from AWS (196GB)
Download annotations from AWS (8MB)
Download images from Azure (196GB)
Download annotations from Azure (8MB)
Having trouble downloading? Check out our FAQ.

Forest Damages - Larch Casebearer
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/larch-casebearer
Overview
The larch casebearer, Coleophora laricella, is a moth that mainly attacks larch trees and has caused significant damage in larch stands in Västergötland, Sweden.
The Swedish Forest Agency, supported by Microsoft’s AI for Earth program, started a project that utilizes artificial intelligence for identifying, inventorying, mapping, and monitoring forest areas affected by the larch casebearer. The primary intention of the project is to help forest caretakers to quickly identify threats and react to prevent further forest damage.
This dataset is an outcome of the project, and it contains 1,543 images taken from two drone flying occasions over five affected areas in Västergötland, Sweden. The data set is structured in 10 batches, numbered 1 to 10.
All batches contain bounding box annotations around trees, categorized as Larch and Other. These annotations can be used to train AI models for tree identification. In 1,543 images, there are 101,878 annotated trees.
Batches 1-5 also contain annotations describing tree damage in four categories: Healthy (H), Light Damage (LD), High Damage (HD), and Other. These annotations can be used to train models for damage classification. In 840 images there are 44,522 larch trees annotated with damage level.
An overview of the project is available here (video).
Figure 1: Data set statistics
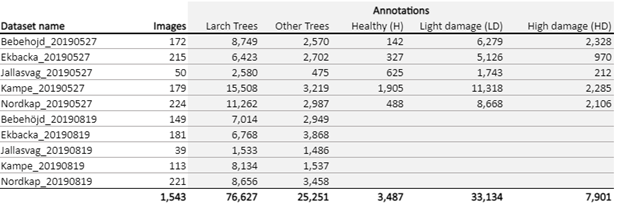
Data format
There are ten folders in the zipfile, each corresponding to a drone survey, named according to:
[area_name]_[capture_date]
- area_name is one of "Bebehojd", "Ekbacka", "Jallasvag", "Kampe", "Nordkap"
- capture_date is the capture date, formatted as yyyymmdd
Within each survey folder are two folders: "Annotations" and "Images".
Image files are named according to:
Images/B[batch_number]_[image_number].JPG
- batch_number is a two-digit batch number, from 01 to 10. Each survey folder contains only a single batch number.
- image_number is a five-digit image number
Annotation files are named according to:
Annotations/B[batch_number]_[image_number].XML
- batch_number is a two-digit batch number, from 01 to 10, which will match the corresponding "Images" folder.
- image_number is a five-digit image number
Annotations are in the Pascal VOC XML format for objection detection. A typical individual tree object would be annotated as:
Larch
LD
Unspecified
0
0
164
107
347
380
Citation
If you use these data in a publication or report, please use the following citation:
Swedish Forest Agency (2021): Forest Damages - Larch Casebearer 1.0. National Forest Data Lab. Dataset.
Contact information
For questions about this data set, contact Halil Radogoshi (halil.radogoshi@skogsstyrelsen.se) at the Swedish Forest Agency.
License
Labels
The organizations responsible for generating and funding this dataset make no representations of any kind including, but not limited to the warranties of merchantability or fitness for a particular use, nor are any such warranties to be implied with respect to the data. Although every effort has been made to ensure the accuracy of information, errors may be reflected in data supplied. The user must be aware of data conditions and bear responsibility for the appropriate use of the information with respect to possible errors, collection methodology, currency of data, and other conditions. Credit should always be given to the data source when this data is transferred, altered, or used for analysis.
Labels are released under the Community Data License Agreement (permissive variant).
Images
For the drone images, the Swedish Forest Agency has secured permit for dissemination of geographical data from Lantmäteriet, an authority belonging to Ministry of Finance in Sweden.
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (3.3GB)
Download from AWS (3.3GB)
Download from Azure (3.3GB)
Having trouble downloading? Check out our FAQ.
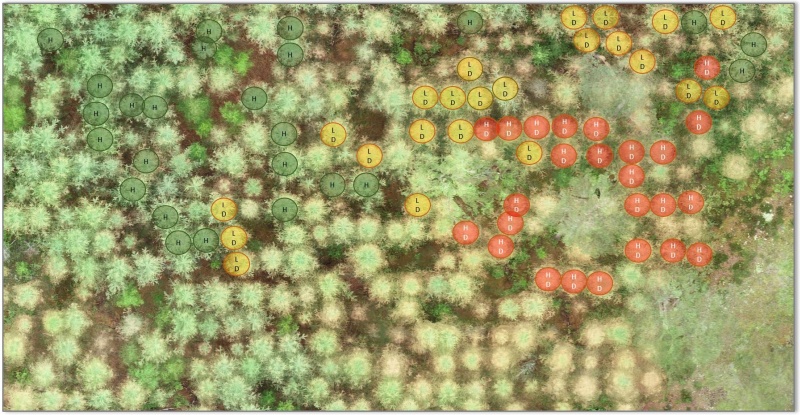
Boxes on Bees and Pollen
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/boxes-on-bees
Overview
The goal of the BeeLivingSensor project is to non-invasively track honey bees at hive entrances, and to track the type and volume of pollen they bring into the hive. By analyzing the color of the pollen and aggregating it with other data, the project aims to to determine the plant biodiversity around the beehive.
This data set contains approximately 5,000 images of bees annotated with bounding boxes on both bees and pollen, for a total of around 50,000 annotations.
Data format
The zipfile linked below contains 4993 image files, each of which is associated with an .xml file of the same name. For example, "Chueried_Churied_01_ST_216.xml" contains the annotations for the image "Chueried_Churied_01_ST_216.jpg".
Annotations are in the Pascal VOC XML format for objection detection. A typical individual bee object, for example, would be annotated as:
bee
Unspecified
0
0
1550
1216
1675
1282
Citation
If you use these data in a publication or report, please use the following citation:
Noninvasive bee tracking in videos: deep learning algorithms and cloud platform design specifications. Dataset, 2021.
Contact information
For questions about this data set, contact the project team via the project's contact form.
License
This data set is released under the Community Data License Agreement (permissive variant).
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (2GB)
Download from AWS (2GB)
Download from Azure (2GB)
Having trouble downloading? Check out our FAQ.

NOAA Arctic Seals 2019
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/noaa-kotz
Overview
This dataset consists of around 80,000 color and IR (thermal) images, associated with flights conducted in Alaska by the NOAA Alaska Fisheries Science Center in 2019. Images have been annotated with around 28,000 bounding boxes (14,000 on color images, 14,000 on thermal images) on ice seals.
Data format
Metadata are provided as a .csv file, in which each row represents a detection (a bounding box on an RGB image and the corresponding thermal image); important columns include:
- detection_type: class associated with this bounding box, e.g. "ringed_seal", "ringed_pup"
- rgb_left,rgb_right,rgb_top,rgb_bottom: bounding box location in absolute (pixel) coordinates on the RGB image; the origin of the bounding box is in the upper-left of the image, so "bottom" is the smaller of the two y coordinates, but represents the logical "top" of the bounding box
- ir_left,ir_right,ir_top,ir_bottom: bounding box location in absolute (pixel) coordinates on the IR image; the origin of the bounding box is in the upper-left of the image, so "bottom" is the smaller of the two y coordinates, but represents the logical "top" of the bounding box
- rgb_image_path: path to the RGB image associated with this detection within the blob container linked below
- ir_image_path: path to the IR image associated with this detection within the blob container linked below
Citation
If you use these data in a publication or report, please use the following citation:
Alaska Fisheries Science Center, 2021: A Dataset for Machine Learning Algorithm Development.
Contact information
For questions about this data set, contact Erin Moreland and Stacie Hardy at NOAA Fisheries.
License
This data set is released under the Community Data License Agreement (permissive variant).
Accessing the data
Annotations are available here:
surv_test_kamera_detections_20210212_full_paths.csv
A list of all files in the data set - including empty images with no annotations - is available here:
Images are available in the following cloud storage containers:
- gs://public-datasets-lila/noaa-kotz (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/noaa-kotz (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/noaa-kotz (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, the image referred to in the metadata file as:
Images/fl04/CENT/test_kotz_2019_fl04_C_20190510_000310.667291_rgb.jpg
...is available at any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.

Leopard ID 2022
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wild-me/leopard.coco.tar.gz
Overview
This data set contains images of African leopards (Panthera pardus) with bounding boxes and individual animal identifications. This dataset represents a collaborative effort based on the data collection and population modeling efforts conducted by Botswana Predator Conservation Trust and Kasim Rafiq from 2011-2022. Photos (6,795) and metadata from various leopard encounters were collected. Images were annotated with bounding boxes around each visible leopard and viewpoints were labeled (e.g., left, right, etc.). A total of 430 individual leopard were identified by their unique spot patterning using first computer-assisted spot pattern recognition and then manual review and confirmation. A total of 6,805 named sightings were exported.
Data format
The dataset is released in the Microsoft COCO .json format. We have collapsed the entire dataset into a single “train” label and have left “val” and “test” empty; we do this as an invitation to researchers to experiment with their own novel approaches for dealing with the unbalanced and chaotic distribution on the number of sightings per individual. All of the images in the dataset have been resized to have a maximum dimension of 2,400 pixels. The metadata for all animal sightings is defined by an axis-aligned bounding box and includes information on the rotation of the box (theta), the viewpoint of the animal, a species (category) ID, a source image ID, an individual string ID name, and other miscellaneous values. The temporal ordering of the images can be determined from the metadata for each image.
Citation, license, and contact information
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
If you use this dataset in published work, please cite as:
Botswana Predator Conservation Trust (2022). Panthera pardus CSV custom export. Retrieved from African Carnivore Wildbook 2022-04-28.
Downloading the data
Data download links:
- Download from GCP (8GB)
- Download from AWS (8GB)
- Download from Azure (8GB)
Having trouble downloading? Check out our FAQ.

Hyena ID 2022
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wild-me/hyena.coco.tar.gz
Overview
This data set contains images of spotted hyena (Crocuta crocuta) with bounding boxes and individual animal identifications. This dataset represents a collaborative effort based on the data collection and population modeling efforts conducted by the Botswana Predator Conservation Trust. Photos (3,104) and metadata from various hyena encounters were collected. Images were annotated with bounding boxes around each visible hyena and viewpoints were labeled (e.g., left, right, etc.). A total of 256 individual spotted hyena were identified by their unique spot patterning using first computer-assisted spot pattern recognition and then manual review and confirmation. A total of 3,129 named sightings were exported.
Data format
The dataset is released in the Microsoft COCO .json format. We have collapsed the entire dataset into a single “train” label and have left “val” and “test” empty; we do this as an invitation to researchers to experiment with their own novel approaches for dealing with the unbalanced and chaotic distribution on the number of sightings per individual. All of the images in the dataset have been resized to have a maximum dimension of 2,400 pixels. The metadata for all animal sightings is defined by an axis-aligned bounding box and includes information on the rotation of the box (theta), the viewpoint of the animal, a species (category) ID, a source image ID, an individual string ID name, and other miscellaneous values. The temporal ordering of the images can be determined from the metadata for each image.
Citation, license, and contact information
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
If you use this dataset in published work, please cite as:
Botswana Predator Conservation Trust (2022). Panthera pardus CSV custom export. Retrieved from African Carnivore Wildbook 2022-04-28.
Downloading the data
Data download links:
- Download from GCP (3GB)
- Download from AWS (3GB)
- Download from Azure (3GB)
Having trouble downloading? Check out our FAQ.

Beluga ID 2022
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/wild-me/beluga.coco.tar.gz
Overview
This data set contains Beluga whales (Delphinapterus leucas) with pre-cropped images and individual animal identifications. This dataset represents a collaborative effort based on the data collection and population modeling efforts conducted in the Cook Inlet off the cost of Alaska from 2016-2019. The photos (5,902) and metadata from 1,617 unique encounters (within 1 hour) were collected from boat-based cameras and a camera looking down from above on an aerial drone. Images are annotated with full-image bounding boxes and viewpoints were labeled (top, left, right). A total of 788 individual Beluga whales were identified by hand by trained experts using scarring patterns and other visual markings. This dataset is being released in tandem with the "Where's Whale-do?" ID competition hosted by DrivenData and is identical to the public training set used in that competition.
Data format
The training dataset is released in the Microsoft COCO .json format. We have collapsed the entire dataset into a single “train” label and have left “val” and “test” empty; we do this as an invitation to researchers to experiment with their own novel approaches for dealing with the unbalanced and chaotic distribution on the number of sightings per individual. All of the images in the dataset have been resized to have a maximum dimension of 1,200 pixels. The metadata for all animal sightings is defined by an axis-aligned bounding box and includes information on the viewpoint of the animal, a species (category) ID, a source image ID, an individual string ID name, and other miscellaneous values. The temporal ordering of the images can be determined from the metadata for each image.
Test data was added later, after the competition, and is thus in a different format. Contact the dataset owner for questions about the test data.
Citation, license, and contact information
For research or press contact, please direct all correspondence to Wild Me at info@wildme.org. Wild Me is a registered 501(c)(3) not-for-profit based in Portland, Oregon, USA and brings state-of-the-art computer vision tools to ecology researchers working around the globe on wildlife conservation.
This dataset is released under the Community Data License Agreement (permissive variant).
Downloading the data
Data download links for the train split:
- Download the train split from GCP (563MB)
- Download the train split from AWS (563MB)
- Download the train split from Azure (563MB)
Data download links for the test split:
- Download the test split from GCP (117MB)
- Download the test split from AWS (117MB)
- Download the test split from Azure (117MB)
Having trouble downloading? Check out our FAQ.

NOAA Puget Sound Nearshore Fish 2017-2018
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/noaa-psnf
Overview
This data set contains 77,739 images sampled from video collected on and around shellfish aquaculture farms in an estuary in the Northeast Pacific, in which 67,990 objects (fish and crustaceans) have been annotated on 30,384 images (the remainder have been annotated as "empty"). Boxes are on individual objects, but labeling was done at the image level, so objects are labeled as one of "fish", "crab", or "fish_and_crab", where "fish_and_crab" means that both categories were present in this image.
This data set was used to develop a computer vision model to detect fish, allowing specialists from NOAA to examine images in which fish were detected to classify and quantify their species more efficiently. Incorporating artificial intelligence into ecological and resource management fields will advance our understanding of potential changes in the marine environment in the context of fisheries and aquaculture expansion, shoreline development, and climate change.
These data were collected in a collaborative effort between the NOAA Northwest Fisheries Science Center, The Nature Conservancy, and shellfish aquaculture farms in WA, USA. Funding was provided by the NOAA Office of Aquaculture Grant (NA17OAR4170218) and Washington Sea Grant (UWSC10159). The data were labelled in a collaborative effort between the NOAA Northwest Fisheries Science Center and the Microsoft AI for Good Research Lab.
Code for fine-tuning YOLOv5 on this data is available here.
Citation, license, and contact information
If you use these data in a publication or report, please use the following citation to refer to the data collection process:
Ferriss B, Veggerby K, Bogeberg M, Conway-Cranos L, Hoberecht L, Kiffney P, Litle K, Toft J, Sanderson B. Characterizing the habitat function of bivalve aquaculture using underwater video. Aquaculture Environment Interactions. 2021 Nov 18;13:439-54.
...and/or the following citation to refer to the annotations and public data set:
Farrell DM, Ferriss B, Sanderson B, Veggerby K, Robinson L, Trivedi A, Pathak S, Muppalla S, Wang J, Morris D, Dodhia R. A labeled data set of underwater images of fish and crab species from five mesohabitats in Puget Sound WA USA. Scientific Data. 2023 Nov 13;10(1):799.
For questions about this data set, contact Beth Sanderson (NOAA Northwest Fisheries Science Center) and Bridget Ferriss (NOAA Alaska Fisheries Science Center).
This data set is released under the Community Data License Agreement (permissive variant).
Data format
Annotations are provided in COCO Camera Traps .json format.
Some deployments used a green-blocking filter; the Boolean "filter" property on each image in the dataset indicates whether that images was captured with a filter.
Downloading the data
Download links:
Download images from GCP (7GB)
Download annotations from GCP (4MB)
Download images from AWS (7GB)
Download annotations from AWS (4MB)
Download images from Azure (7GB)
Download annotations from Azure (4MB)
Having trouble downloading? Check out our FAQ.

Izembek Lagoon Waterfowl
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/izembek-lagoon-birds
Overview
This dataset contains 9,267 high-resolution (8688x5792) aerial images from Izembek Lagoon in Alaska, collected to survey waterfowl. The dataset includes 521,270 bounding boxes on waterfowl, with each box identified as one of:
- Brant (424,790 boxes)
- Canada goose (47,561 boxes)
- Gull (5,631 boxes)
- Emperor goose (2,013 boxes)
- Other (5,631 boxes)
All were originally annotated as points, and were converted to boxes as a convenience for detector training. Consequently, the boxes are all identical in size, centered on the original annotation points and sized to the typical size of birds in these images. Approximately half of the images (4,281) are annotated as empty.
This dataset is a subset of the Aerial Photo Imagery from Fall Waterfowl Surveys dataset; all non-empty images from the original dataset are included, but only a small fraction of the empty images are included. The original dataset is the dataset of record; the present dataset is provided as a convenience for training AI models, as (a) some effort was required to convert the annotations to a standard format (import code), and (b) the original dataset is quite large (1.82TB). Because the proportion of empty images has been dramatically reduced in the present dataset, models trained on the subset should be evaluated against the original dataset before making claims about precision and recall as they would apply in a real-world setting.
Citation
If you use this dataset, please cite the original dataset:
Weiser EL, Flint PL, Marks DK, Shults BS, Wilson HM, Thompson SJ, Fischer JB, 2022, Aerial photo imagery from fall waterfowl surveys, Izembek Lagoon, Alaska, 2017-2019: U.S. Geological Survey data release, https://doi.org/10.5066/P9UHP1LE.
Data format
Annotations are provided in COCO Camera Traps format.
Downloading the data
Metadata is available here.
Images are available as a single zipfile:
Download from GCP (124GB)
Download from AWS (124GB)
Download from Azure (124GB)
Images are also available (unzipped) in the following cloud storage folders:
- gs://public-datasets-lila/izembek-lagoon-birds/images (GCP)
- s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/izembek-lagoon-birds/images (AWS)
- https://lilawildlife.blob.core.windows.net/lila-wildlife/izembek-lagoon-birds/images (Azure)
We recommend downloading images (the whole folder, or a subset of the folder) using gsutil (for GCP), aws s3 (for AWS), or AzCopy (for Azure). For more information about using gsutil, aws s3, or AzCopy, check out our guidelines for accessing images without using giant zipfiles.
If you prefer to download images via http, you can. For example, one image (with lots of birds) appears in the metadata as:
2017_Replicate_2017-09-30_Cam2_CAM24430.JPG
This image can be downloaded directly from any of the following URLs (one for each cloud):
{kind=link}
{kind=link}
{kind=link}
Having trouble downloading? Check out our FAQ.

Sea Star Re-ID 2023
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/sea-star-re-id
Overview
This data set contains 1,204 images of 39 individual Asterias rubens sea stars (ASRU) and 983 images of 56 individual Anthenea australiae (ANAU) sea stars. For the ASRU data set, images were taken on five distinct days. For the ANAU data set, images were taken in three locations (sunlight, shaded, naturalistic exhibit) on the same day.
Citation, license, and contact information
If you use this dataset, please cite:
Wahltinez O, Wahltinez S. 2023. An Open-Source General Purpose Machine Learning Framework for Individual Animal Re-Identification Using Few-Shot Learning. Methods in Ecology and Evolution, 2024.
For questions about this dataset, contact Oscar Wahltinez.
This data set is released under the Community Data License Agreement 1.0 (permissive variant).
Data format
Images are classified into folders; each folder contains all the images from a single individual. Folders beginning with "Asru" contain images of Asteria rubens; folders beginning with "Anau" contain images of Anthenea australiae.
For sample code that uses this data, see:
https://github.com/owahltinez/triplet-loss-animal-reid
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (1.7GB)
Download from AWS (1.7GB)
Download from Azure (1.7GB)
Having trouble downloading? Check out our FAQ.

UAS Imagery of Migratory Waterfowl at New Mexico Wildlife Refuges
S3 base
s3://us-west-2.opendata.source.coop/agentmorris/lila-wildlife/uas-imagery-of-migratory-waterfowl/uas-imagery-of-migratory-waterfowl.20240220.zip
Overview
These data were collected as part of Drones for Ducks, a co-operative agreement between the US Fish and Wildlife Service and the Center for the Advancement of Spatial Informatics Research and Education (ASPIRE) at the University of New Mexico. UAS images were collected at wildlife areas in New Mexico in November and December 2018. Fifteen biologists from the US Fish and Wildlife Service annotated a twelve-image subset of UAS imagery of waterbirds collected at Bosque del Apache National Wildlife Refuge through the online image annotation platform Labelbox. These benchmark images were chosen to maximize species diversity and include a variety of vegetation and habitat types in the background.
Each observer drew polygons around individual birds and selected an identification from a list of twelve species names, which was derived from a previous survey at the site and refined via consultation with National Refuge System biologists. Anonymized observer ID is preserved in the raw annotations as "labeler_id". This dataset includes both raw annotations and consensus annotations. To derive the consensus annotations, a Density-Based Spatial Clustering of Applications with Noise (DBSCAN) clustering algorithm was used to identify groups of bounding boxes associated with individual animals; the median coordinates of the bounding boxes implicated in each cluster were used to derive the consensus bounding box. Then, the mode species classification for each cluster was used to define the classification for the cluster to produce a consensus annotation.
Paired with these are annotations produced by volunteers using the participatory science platform, Zooniverse. Instead of species categories, volunteers labeled birds by morphological class: Duck, Goose, or Crane. Raw annotations and consensus annotations derived using the process described above are provided.
Citation, license, and contact information
If you use this dataset, please cite:
Converse RC, Lippitt CD, Sesnie SE, Harris GM, Butler MG, Stewart DR. Observer variability in manual-visual interpretation of UAS imagery of wildlife, with insights for deep learning applications. In review.
For questions about this data set, contact the Center for the Advancement of Spatial Informatics Research and Education at aspire@unm.edu.
This data set is released under the CC-BY NC 4.0 license.
Data format
The expert and volunteer datsets described above are in folders called "experts" and "crowdsourced", respectively. Each of those folders contains a folder called "images" and two COCO-formatted .json files, one containing the raw annotations ("raw"), and one containing the consensus annotations ("refined").
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (322MB)
Download from AWS (322MB)
Download from Azure (322MB)
